Simulacrum, từ simulacrum Latin, là một sự bắt chước, giả mạo hoặc hư cấu. Khái niệm này được liên kết với mô phỏng, đó là hành động mô phỏng .Một...
Tiền xử lý dữ liệu trong Machine Learning, ví dụ cụ thể. – Web888 chia sẻ kiến thức lập trình, kinh doanh, mmo
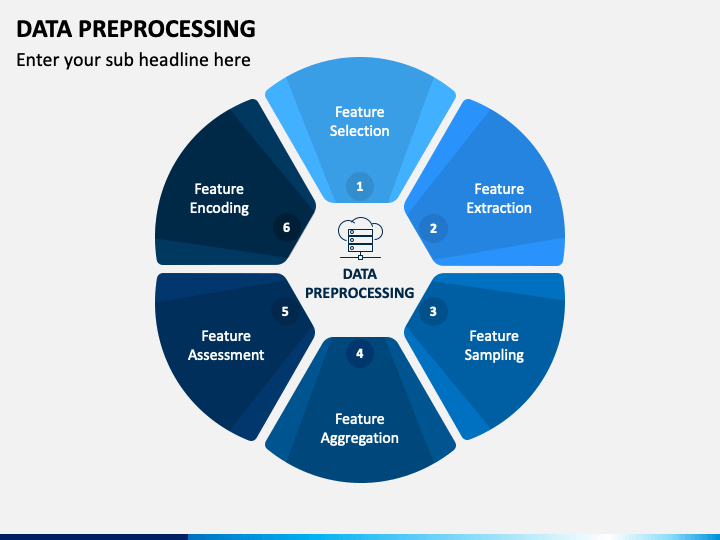 Các phần trong tiền xử lý dữ liệuTiền xử lý dữ liệu là một bước không hề thiếu trong Machline Learning vì như bạn đã biết, dữ liệu là một phần rất quan trọng, ảnh hưởng tác động trực tiếp tới việc Training Model. Do vậy, tiền xử lý dữ liệu trước khi đưa nó vào Model là rất quan trọng, giúp vô hiệu hoặc bù đắp những dữ liệu còn thiếu .
Các phần trong tiền xử lý dữ liệuTiền xử lý dữ liệu là một bước không hề thiếu trong Machline Learning vì như bạn đã biết, dữ liệu là một phần rất quan trọng, ảnh hưởng tác động trực tiếp tới việc Training Model. Do vậy, tiền xử lý dữ liệu trước khi đưa nó vào Model là rất quan trọng, giúp vô hiệu hoặc bù đắp những dữ liệu còn thiếu .Trong bài viết này tôi sẽ giúp bạn hiểu được những xử lý dữ liệu trước khi đưa vào quy mô như thế nào trải qua một ví dụ đơn cử chứ không chỉ là lý thuyế khô khan .
Đầu tiền chắc như đinh là cần tập dữ liệu để những bạn thực hành thực tế .
Chuẩn bị dữ liệu.
Các bạn có thể lấy dữ liệu theo link dưới đây. Thì đơn giản đây là dữ liệu gồm 10 row và 4 column, phần sau bạn sẽ hiểu tại sao tôi lại chọn dữ liệu gồm 10 row để thực thi. Dữ liệu thống kê hành vi mua xe của một số người trên các quốc gia, có độ tuổi và mức lương khác nhau. Trong đó cũng có ,một vài dữ liệu bị mất.
Bạn đang đọc: Tiền xử lý dữ liệu trong Machine Learning, ví dụ cụ thể. – Web888 chia sẻ kiến thức lập trình, kinh doanh, mmo
dataset = pd.read_csv("data.csv")
Country Age Salary Purchased
0 France 44.0 72000.0 No
1 Spain 27.0 48000.0 Yes
2 Germany 30.0 54000.0 No
3 Spain 38.0 61000.0 No
4 Germany 40.0 NaN Yes
5 France 35.0 58000.0 Yes
6 Spain NaN 52000.0 No
7 France 48.0 79000.0 Yes
8 Germany 50.0 83000.0 No
9 France 37.0 67000.0 YesTách dữ liệu
Xử dụng hàm. iloc [ ] trong pandas.core để cắt dữ liệu, xác lập được đâu là features và đâu là output .
Ví dụ : X = dataset.iloc [ : 3, : – 1 ] / / cắt từ 3 số 1 và bỏ cột cuối .
Country Age Salary
0 France 44.0 72000.0
1 Spain 27.0 48000.0
2 Germany 30.0 54000.0
Và để xử lý dữ liệu thì bạn phải chuyển về numpy array với hàm X = dataset.iloc [ : 3, : – 1 ]. values .
Tiền xử lý dữ liệu
Sau đây sẽ là 1 số ít khái niệm tôi dùng trong bài viết này :
- Xử lý Missing Data
- Standardization (Phân phối chuẩn)
- Handling Catogrical Variables
- One-hot Encoding
- Multicollinearity
1. Xử lý Missing Data
Trên bất kỳ loại dataset nào trên quốc tế đều có những few null values. Điều đó thì thực sự không tốt khi bạn muốn sử dụng những quy mô như regression ( hồi quy ) hay classification ( phân lớp ) hay bất kể những quy mô khác. Chú ý : Trong Python thì NULL cũng được trình diễn bằng NAN. Do vậy chúng hoàn toàn có thể được sử dụng thay thế sửa chữa cho nhau .
Bạn hoàn toàn có thể tự triển khai code bằng cách dùng vòng lặp duyệt quan những thành phần của từng cột xem cột nào có giá trị tương tự isnull ( ) và xử lý .
Trong ví dụ này tôi sẽ hướng dẫn bạn xử dụng thư viện Sklearn giúp bạn thuận tiện xử lý những missing data. SimpleImputer là một class của Sklearn nó tương hỗ xử lý những missing data là số và thay chúng là một giá trị trung bình của cột, tần suất của dữ liệu suất hiện nhiều nhất, …
from sklearn.impute import SimpleImputer #Create an instance of Class SimpleImputer: np.nan is the empty value in the dataset imputer = SimpleImputer(missing_values=np.nan, strategy='mean') #Replace missing value from numerical Col 1 'Age', Col 2 'Salary' imputer.fit(X[:, 1:3]) #transform will replace & return the new updated columns X[:, 1:3] = imputer.transform(X[:, 1:3])
2. Xử lý categorical data
Encode Independent Variables: Giúp chúng ta convert một cột chứa các String thành vector 0 & 1
- Xử dụng ColumnTransformer class và OneHotEncoder của sklearn.
 One-hot code
One-hot code
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoderTạo một tuple (‘encoder’ encoding transformation, instance của class OneHotEncoder, [cols muốn transform) và các cols khác bạn không muốn làm gì tới nó thì có thể dùng remainder=”passthrough” để bỏ qua chúng.
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder="passthrough" )
Fit và transform với input = X và instance ct của class ColumnTransformer
#fit and transform with input = X #np.array: need to convert output of fit_transform() from matrix to np.array X = np.array(ct.fit_transform(X))
Sau khi converting ta được France = [ 1.0,0. 0,0. 0 ] những là đã được one-hot .
Encode Dependent Variables: Nghĩa là chúng ta phải mã hóa các nhãn đầu ra cho máy hiểu.
- Sử dụng Label Encoder để mã hóa các nhãn
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() #output of fit_transform of Label Encoder is already a Numpy Array y = le.fit_transform(y) #y = [0 1 0 0 1 1 0 1 0 1]
Splitting Training set và Test set
- Sử dụng train_test_split của Sklearn-Model Selection để cắt dữ liệu train và test.
- Sử dụng tham số: test_size=… để chia dữ liệu tập test trên toàn bộ dữ liệu.
- random_state = 1: Giúp sử dụng bộ random có sẵn của python.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
Feature Scaling
Tại sao lại xảy ra FS : Khi mà tất cả chúng ta khám phá dữ liệu thì hoàn toàn có thể có một số ít feature có độ lớn hơn hẳn những feature khác do vậy features nhỏ hơn chắc như đinh sẽ bị bỏ lỡ khi tất cả chúng ta thực thi ML Model .
# Note 1 : FS không cần vận dụng cho Multi-Regression models vì khi y Dự kiến = b0 + b1 * x1 + b2 * x2 + … + bn * xn thì khi đó ( b0, b1, …, bn ) là những thông số để bù lại cho việc chênh lệnh do vậy không cần FS .
# Note 2 : Đối với những Categorical Features Encoding cũng không cần vận dụng FS .
 Feature Scaling.# Note3 : FS phải được thực thi sau khi splitting Training và Test sets. Do nếu tất cả chúng ta sử dụng FS trước khi splitting training và test sets thì dữ liệu sẽ bị mất đi tính đúng .
Feature Scaling.# Note3 : FS phải được thực thi sau khi splitting Training và Test sets. Do nếu tất cả chúng ta sử dụng FS trước khi splitting training và test sets thì dữ liệu sẽ bị mất đi tính đúng .
Vậy làm sao để feature scaling.
Có 2 kĩ thuật để làm điều này là :
- Standardisation: Biến đổi dữ liệu sao cho giá trị trung bình là 0 và standard deviation là 1.
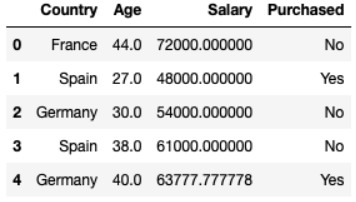 Bộ dữ liệu bên trênTrên dữ liệu này bạn hoàn toàn có thể thấy số Age và Salary có độ chênh lệnh nhau khá nhiều do vậy dữ liệu của Age hoàn toàn có thể không được sử dụng trong Model. Do vậy tất cả chúng ta cần chuẩn hóa dữ liệu đưa chúng về số nhỏ hơn và vẫn bảo vệ tính đối sánh tương quan của dữ liệu .
Bộ dữ liệu bên trênTrên dữ liệu này bạn hoàn toàn có thể thấy số Age và Salary có độ chênh lệnh nhau khá nhiều do vậy dữ liệu của Age hoàn toàn có thể không được sử dụng trong Model. Do vậy tất cả chúng ta cần chuẩn hóa dữ liệu đưa chúng về số nhỏ hơn và vẫn bảo vệ tính đối sánh tương quan của dữ liệu .
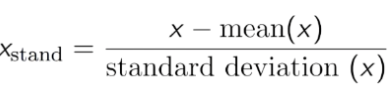 Công thức StandardisationBạn hoàn toàn có thể sử dụng StandardScaler của sklearn.preprocessing để Std cho dữ liệu .
Công thức StandardisationBạn hoàn toàn có thể sử dụng StandardScaler của sklearn.preprocessing để Std cho dữ liệu .
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train[:,3:] = sc.fit_transform(X_train[:,3:]) #only use Transform to use the SAME scaler as the Training Set X_test[:,3:] = sc.transform(X_test[:,3:])
- Normalisation: Làm cho tập dữ liệu giao động trong khoảng từ 0 đến 1.
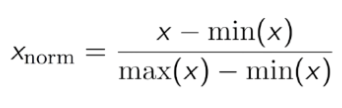 Công thức normalisation
Công thức normalisation
Source: https://vh2.com.vn
Category : Tin Học

Khởi động sao tam giác là một trong số những phương pháp để khởi động động cơ đơn giản, hiệu quả và tiết kiệm chi phí. Vậy Khởi động sao...
Đồ Án 2: Thiết kế mạch Buck Converter DC-DC Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây...
Nguyên tắc hoạt động máy phát điện xoay chiềuDựa trên hiện tượng cảm ứng điện từ: Khi từ thông qua một vòng dây biến thiên điều hòa, trong vòng dây...
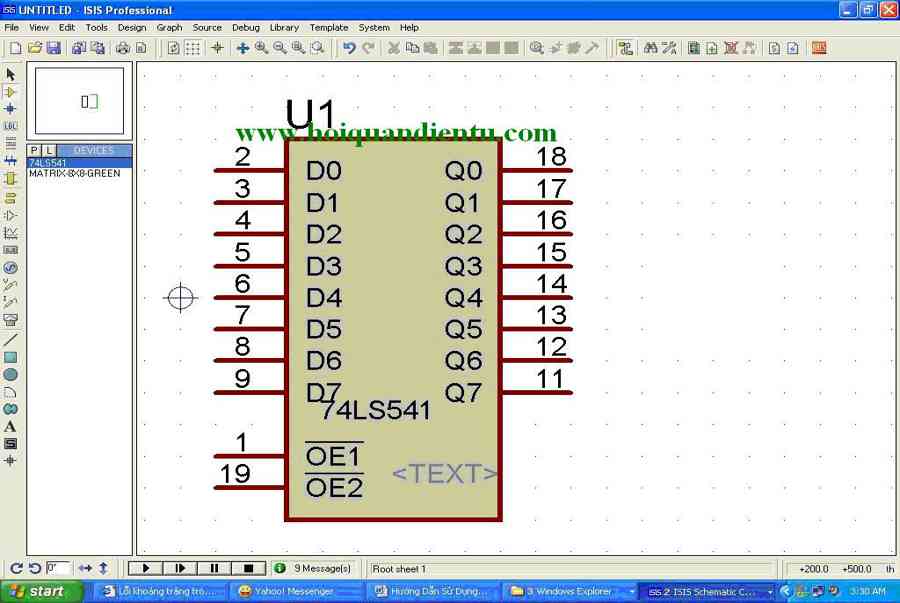
HDSD Led matrix Trong Proteus Và Cách Quét LED SD 8051 ( 8 x 64 ) Ngày 03/08/2010 20:19:50 / Lượt xem: 27279 / Người đăng: biendt / Nguồn: [email protected]...