Lý thuyết Dòng điện trong chân không hay, chi tiết nhất Bài viết Lý thuyết Dòng điện trong chân không với giải pháp giải cụ thể giúp học viên ôn...
Nvidia Ampere vs AMD RDNA 2 – Cuộc chiến của các kiến trúc
Nvidia Ampere vs AMD RDNA 2 – Battle of the Architectures
Đối với những người dùng công nghệ tiên tiến đam mê GPU, đã phải chờ đón rất lâu. Nvidia giữ dòng Turing hoạt động giải trí trong hai năm trước khi thay thế sửa chữa nó bằng Ampere vào tháng 9 năm 2020. AMD thì lại khoảng cách 15 tháng giữa những phiên bản mới của họ, nhưng hầu hết mọi người không chăm sóc đến điều đó .
Những gì họ muốn thấy là AMD tung ra một quy mô đầu cuối để cạnh tranh đối đầu trực tiếp với những gì tốt nhất từ Nvidia. Họ đã làm điều đó và giờ đây tất cả chúng ta đã thấy hiệu quả, những game thủ PC giờ đây hoàn toàn có thể tha hồ lựa chọn ( tối thiểu là về mặt triết lý ), khi chi tiền của họ cho những card đồ họa có hiệu suất tốt nhất .
Nhưng những gì về việc cung cấp năng lượng cho các con chip của chúng? Một trong số chúng về cơ bản có tốt hơn cái còn lại không?
Đọc tiếp để xem Ampere và RDNA 2 chiến đấu như thế nào!
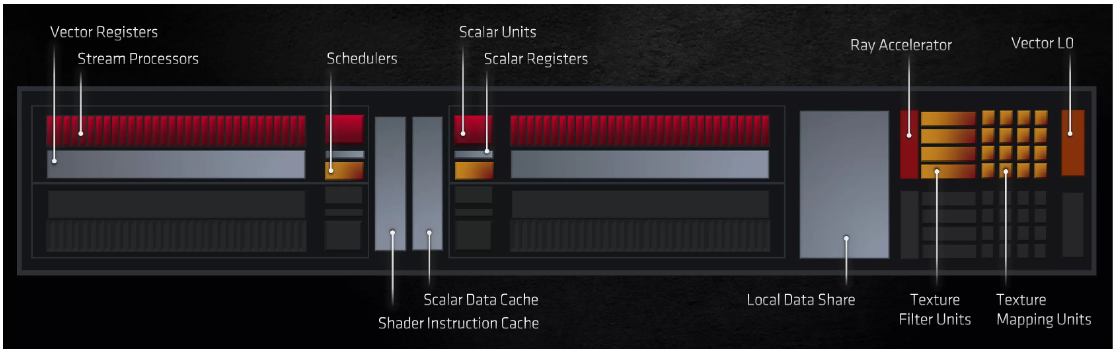
Nvidia thu nhỏ, AMD tăng trưởng
Kích thước Nodes và khuôn
Các dòng mẫu sản phẩm GPU hạng sang đã lớn hơn rất nhiều so với CPU trong nhiều năm qua và size cảu chúng đang tăng dần theo năm tháng. Sản phẩm mới nhất của AMD có diện tích quy hoạnh khoảng chừng 520 mm 2, gấp đôi kích cỡ của chip Navi trước đó của họ. Tuy nhiên, nó không phải là phiên bản lớn nhất mà họ có – niềm vinh dự đó thuộc về GPU trong bộ tăng cường MI100 Instinct mới của họ, vào thời gian 750 mm 2 .
Lần ở đầu cuối AMD sản xuất bộ giải quyết và xử lý chơi game có kích cỡ gần bằng với Navi 21 là dành cho card Radeon R9 Fury và Nano, sử dụng kiến trúc GCN 3.0 trong chip Fiji. Nó có kích cỡ 596 mm 2 trong khu vực khuôn, nhưng nó được sản xuất trên nút tiến trình 28HP của TSMC .
AMD đã sử dụng quá trình N7 nhỏ hơn nhiều của TSMC kể từ năm 2018 và chip lớn nhất từ dây chuyền sản xuất sản xuất đó là Vega 20 ( như được tìm thấy trong Radeon VII ), với diện tích quy hoạnh 331 mm 2. Tất cả những GPU Navi của họ đều được sản xuất trên một phiên bản update nhẹ của tiến trình đó, được gọi là N7P, thế cho nên hoàn toàn có thể so sánh những mẫu sản phẩm này .

Radeon R9 Nano : thẻ nhỏ, GPU lớn

Nhưng khi nói đến size khuôn mẫu tuyệt đối, Nvidia chiếm ngôi vương, không nhất thiết phải như vậy mới là tốt. Chip dựa trên Ampere mới nhất, GA102, là 628 mm 2. Nó thực sự nhỏ hơn khoảng chừng 17 % so với tiền thân của nó, TU102 – GPU có diện tích quy hoạnh đáng kinh ngạc 754 mm 2 .
Cả hai đều có size nhạt hơn khi so sánh với chip GA100 khổng lồ của Nvidia – được sử dụng trong AI và TT tài liệu, GPU này có kích cỡ 826 mm 2 và đó là chip TSMC N7. Mặc dù chưa khi nào được phong cách thiết kế để phân phối nguồn năng lượng cho card đồ họa máy tính để bàn, nhưng nó cho thấy quy mô sản xuất GPU hoàn toàn có thể đạt được .
Đặt tổng thể chúng cạnh nhau sẽ làm điển hình nổi bật mức độ cồng kềnh của GPU lớn nhất của Nvidia. Navi 21 trông khá mảnh mai, mặc dầu có nhiều thứ cho một bộ giải quyết và xử lý hơn là chỉ khu vực chết. GA102 đang đóng gói khoảng chừng 28,3 tỷ bóng bán dẫn, trong khi chip mới của AMD có ít hơn 5 %, ở mức 26,8 tỷ .

Những gì tất cả chúng ta không biết là mỗi GPU được kiến thiết xây dựng bao nhiêu lớp, thế cho nên toàn bộ những gì tất cả chúng ta hoàn toàn có thể so sánh là tỷ suất bóng bán dẫn trên diện tích quy hoạnh khuôn, thường được gọi là tỷ lệ khuôn. Navi 21 có khoảng chừng 51,5 triệu bóng bán dẫn trên mỗi mm vuông, nhưng GA102 có số lượng thấp hơn đáng kể ở mức 41,1 – hoàn toàn có thể là chip của Nvidia được xếp chồng lên nhau cao hơn một chút ít so với của AMD, nhưng nó có nhiều năng lực là một tín hiệu của nút quy trình .
Như đã đề cập, Navi 21 được sản xuất bởi TSMC, sử dụng giải pháp sản xuất N7P của họ, giúp tăng hiệu suất một chút ít so với N7 ; nhưng so với mẫu sản phẩm mới của họ, GA102, Nvidia đã chuyển sang cho Samsung làm trách nhiệm sản xuất. Gã khổng lồ bán dẫn Nước Hàn đang sử dụng một phiên bản đã được điều khiển và tinh chỉnh, dành riêng cho Nvidia, của cái gọi là nút 8 nm của họ ( được dán nhãn là 8N hoặc 8NN ) .
Các giá trị nút này, 7 và 8, không tương quan nhiều đến size thực của những thành phần với chip : chúng chỉ đơn thuần là những thuật ngữ tiếp thị, được sử dụng để phân biệt giữa những kỹ thuật sản xuất khác nhau. Điều đó nói rằng, ngay cả khi GA102 có nhiều lớp hơn Navi 21, size khuôn vẫn có một ảnh hưởng tác động đơn cử .

Một tấm wafer 300 mm ( 12 inch ) đang được thử nghiệm trong nhà máy sản xuất sản xuất TSMC .
Bộ vi giải quyết và xử lý và những chip khác được sản xuất từ những đĩa tròn, lớn bằng silicon tinh chế cao và những vật tư khác, được gọi là tấm xốp. TSMC và Samsung sử dụng đĩa đệm 300 mm cho AMD và Nvidia, và mỗi đĩa sẽ tạo ra nhiều chip hơn sử dụng những khuôn nhỏ hơn so với những đĩa lớn hơn .
Sự độc lạ có vẻ như không quá lớn, nhưng khi mỗi tấm wafer tiêu tốn hàng nghìn đô la để sản xuất, AMD có một lợi thế nhỏ so với Nvidia, khi tiết kiệm ngân sách và chi phí chi phí sản xuất. Tất nhiên, đó là giả định, Samsung hoặc TSMC không thực thi một số ít loại thỏa thuận hợp tác kinh tế tài chính với AMD / Nvidia .
Tất cả những trò tai quái về size khuôn và số lượng bóng bán dẫn này sẽ chẳng có ích lợi gì, nếu bản thân những con chip không giỏi trong những gì chúng được phong cách thiết kế để làm. Vì vậy, hãy cùng khám phá bố cục tổng quan của từng GPU mới và xem bên dưới lớp
Mổ xẻ khuôn
Cấu trúc toàn diện và tổng thể của Ampere GA102 và RDNA 2 Navi 21
Tôi mở màn tò mò những kiến trúc bằng cách xem xét cấu trúc toàn diện và tổng thể của GPU Ampere GA102 và RDNA 2 Navi 21 – những sơ đồ này không cho tôi nhiều thông tin về mọi thứ được sắp xếp vật lý như thế nào, nhưng chúng cho biết rõ ràng về cách nhiều thành phần mà bộ vi giải quyết và xử lý có .
Trong cả hai trường hợp, bố cục tổng quan đều rất quen thuộc, vì chúng về cơ bản là phiên bản lan rộng ra của những người nhiệm kỳ trước đó. Việc thêm nhiều đơn vị chức năng để giải quyết và xử lý những lệnh sẽ luôn làm tăng hiệu suất của GPU, vì ở độ phân giải cao trong những bộ phim bom tấn 3D mới nhất, khối lượng việc làm kết xuất tương quan đến một số lượng lớn những phép tính song song .

Các sơ đồ như vậy rất hữu dụng, nhưng so với nghiên cứu và phân tích đơn cử này, thực sự mê hoặc hơn khi xem xét vị trí những thành phần khác nhau bên trong GPU tự chết. Khi phong cách thiết kế một bộ giải quyết và xử lý quy mô lớn, bạn thường muốn những tài nguyên được san sẻ, ví dụ điển hình như bộ điều khiển và tinh chỉnh và bộ nhớ cache ở vị trí TT, để bảo vệ mọi thành phần đều có cùng một đường dẫn đến chúng .
Các mạng lưới hệ thống giao diện, ví dụ điển hình như bộ điều khiển và tinh chỉnh bộ nhớ cục bộ hoặc đầu ra video, nên đi trên những cạnh của chip để thuận tiện liên kết chúng với hàng nghìn dây riêng không liên quan gì đến nhau link GPU với phần còn lại của card đồ họa .
Dưới đây là những hình ảnh sai màu về cái chết của Navi 21 của AMD và GA102 của Nvidia. Cả hai đều đã được chạy qua 1 số ít giải quyết và xử lý hình ảnh để làm sạch hình ảnh và cả hai đều thực sự chỉ hiển thị một lớp bên trong chip ; nhưng chúng cung ứng cho tất cả chúng ta một cái nhìn tuyệt vời về những bộ phận bên trong của một GPU tân tiến .

Sự độc lạ rõ ràng nhất giữa những phong cách thiết kế là Nvidia đã không tuân theo cách tiếp cận tập trung chuyên sâu so với bố cục tổng quan chip – toàn bộ những bộ điều khiển và tinh chỉnh mạng lưới hệ thống và bộ nhớ đệm chính đều nằm ở dưới cùng, với những đơn vị chức năng logic chạy trong những cột dài. Trước đây họ đã làm điều này, nhưng chỉ với những mẫu tầm trung / thấp hơn .
Ví dụ, Pascal GP106 ( được sử dụng giống như GeForce GTX 1060 ) thực sự là một nửa của GP104 ( từ GeForce GTX 1070 ). Thứ hai là chip lớn hơn, có bộ nhớ đệm và bộ tinh chỉnh và điều khiển ở giữa ; chúng vận động và di chuyển sang một bên trong người đồng đội của nó, nhưng chỉ vì phong cách thiết kế đã bị tách ra .

Đối với toàn bộ những bố cục tổng quan GPU đầu cuối trước đây của họ, Nvidia đã sử dụng một tổ chức triển khai tập trung chuyên sâu cổ xưa. Vậy tại sao lại có sự đổi khác ở đây ? Nó không hề là vì nguyên do giao diện, vì những bộ điều khiển và tinh chỉnh bộ nhớ và mạng lưới hệ thống PCI Express đều chạy xung quanh mép của khuôn .
Nó cũng không phải nguyên do vì nhiệt, vì ngay cả khi phần bộ nhớ đệm / bộ điều khiển và tinh chỉnh của khuôn chạy nóng hơn những phần logic, bạn vẫn muốn nó ở giữa, nơi có nhiều silicon xung quanh để giúp hấp thụ và tản nhiệt. Mặc dù tôi không trọn vẹn chắc như đinh về nguyên do của sự biến hóa này, nhưng tôi hoài nghi rằng đó là do những đổi khác mà Nvidia đã triển khai với những đơn vị chức năng ROP ( kết xuất đầu ra ) trong chip .
Chúng ta sẽ xem xét những điều đó cụ thể hơn sau này, nhưng giờ đây tất cả chúng ta hãy cùng xem xét sự biến hóa trong bố cục tổng quan mặc dầu trông kỳ lạ, nhưng nó sẽ không tạo ra sự độc lạ đáng kể về hiệu suất. Điều này là do kết xuất 3D có rất nhiều độ trễ, thường là do phải chờ tài liệu. Vì vậy, những nano giây bổ trợ được thêm vào bằng cách có một số ít đơn vị chức năng logic xa hơn từ bộ nhớ cache so với những đơn vị chức năng khác, toàn bộ đều bị ẩn trong sơ đồ lớn của mọi thứ .
Trước khi tất cả chúng ta liên tục, tất cả chúng ta nên nhìn nhận lại những đổi khác kỹ thuật mà AMD đã thực thi trong bố cục tổng quan Navi 21, so với Navi 10 cung ứng nguồn năng lượng cho Radeon RX 5700 XT. Mặc dù chip mới có kích cỡ gấp đôi, cả về diện tích quy hoạnh và số lượng bóng bán dẫn, so với chip trước đó, những nhà phong cách thiết kế cũng đã nỗ lực cải tổ vận tốc xung nhịp mà không làm tăng đáng kể điện năng tiêu thụ .
Ví dụ, Radeon RX 6800 XT có xung nhịp cơ bản và xung nhịp tăng tương ứng là 1825 và 2250 MHz, cho TDP là 300 W ; những số liệu tựa như cho Radeon RX 5700 XT là 1605 MHz, 1905 MHz và 225 W. Nvidia cũng đã tăng vận tốc đồng hồ đeo tay với Ampere, nhưng một số ít trong số đó hoàn toàn có thể là do sử dụng nút tiến trình nhỏ hơn và hiệu suất cao hơn .
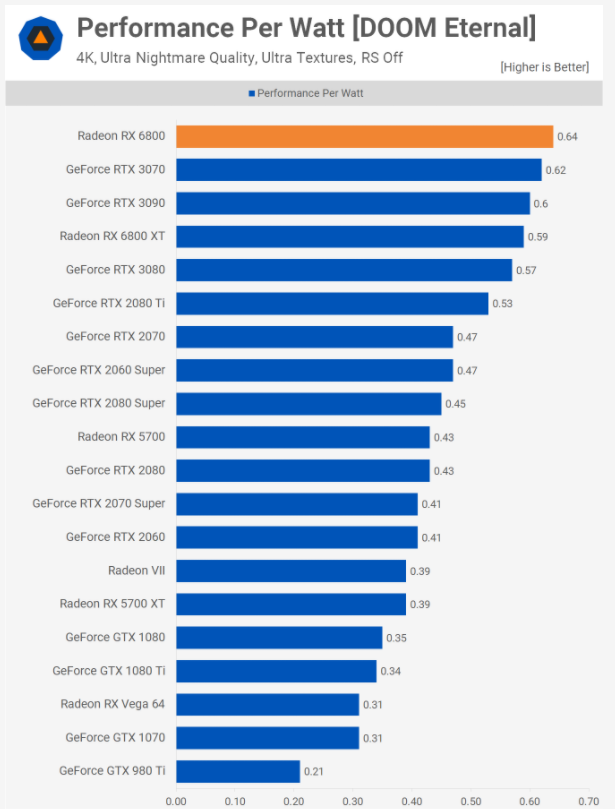
Kiểm tra hiệu suất trên mỗi watt của tôi so với những card Ampere và RDNA 2 cho thấy cả hai nhà cung ứng đều đã có những nâng cấp cải tiến đáng kể trong nghành này, nhưng AMD và TSMC đã đạt được một điều gì đó đáng chú ý quan tâm hơn – so sánh sự độc lạ giữa Radeon RX 6800 và Radeon VII trong Biểu đồ trên .
Sau đó là lần hợp tác GPU tiên phong của họ bằng cách sử dụng nút N7 và trong khoảng chừng thời hạn chưa đầy hai năm, họ đã tăng hiệu suất trên mỗi watt lên 64 %. Nó đặt ra câu hỏi là Ampere GA102 hoàn toàn có thể tốt hơn bao nhiêu nếu Nvidia ở lại với TSMC cho trách nhiệm sản xuất của họ .

Quản lý xí nghiệp sản xuất sản xuất GPU
Cách mọi thứ được tổ chức triển khai bên trong chip
Khi nói đến việc giải quyết và xử lý những lệnh và quản trị việc truyền tài liệu, cả Ampere và RDNA 2 đều tuân theo một quy mô tương tự như như cách mọi thứ được tổ chức triển khai bên trong những chip. Các nhà tăng trưởng game viết mã tiêu đề của họ bằng cách sử dụng API đồ họa, để tạo ra tổng thể những hình ảnh ; nó hoàn toàn có thể là Direct3D, OpenGL hoặc Vulkan. Đây thực ra là những thư viện ứng dụng, chứa đầy ‘ sách ‘ về những quy tắc, cấu trúc và hướng dẫn đơn thuần .
Các trình điều khiển và tinh chỉnh mà AMD và Nvidia tạo ra cho chip của họ về cơ bản hoạt động giải trí như một trình dịch : quy đổi những quy trình tiến độ được cấp qua API thành một chuỗi hoạt động giải trí mà GPU hoàn toàn có thể hiểu được. Sau đó, trọn vẹn nhờ vào vào phần cứng để quản trị mọi thứ, tương quan đến hướng dẫn nào được triển khai trước, phần nào của chip triển khai chúng, v.v.
Giai đoạn quản trị lệnh khởi đầu này được giải quyết và xử lý bởi một tập hợp những đơn vị chức năng, tập trung chuyên sâu một cách hài hòa và hợp lý trong chip. Trong RDNA 2, những trình tạo bóng đồ họa và máy tính được định tuyến qua những đường ống riêng không liên quan gì đến nhau, lập lịch và gửi những hướng dẫn đến phần còn lại của chip ; cái trước được gọi là Graphics Command Processor, cái sau là Asynchronous Compute Engines ( viết tắt là ACE ) .

Nvidia chỉ sử dụng một tên để diễn đạt tập hợp những đơn vị chức năng quản trị của họ, GigaThread Engine và trong Ampere, nó triển khai trách nhiệm tương tự như như với RDNA 2, mặc dầu Nvidia không nói quá nhiều về cách nó thực sự quản trị mọi thứ. Nhìn chung, những bộ giải quyết và xử lý lệnh này hoạt động giải trí giống như một giám đốc sản xuất của một nhà máy sản xuất .
GPU nhận được hiệu suất từ việc thực thi mọi thứ song song, vì thế Lever tổ chức triển khai tiếp theo được nhân đôi trên chip. Gắn bó với sự tương đương về nhà máy sản xuất, đây sẽ giống như một doanh nghiệp có văn phòng TT, nhưng có nhiều khu vực để sản xuất sản phẩm & hàng hóa .
AMD sử dụng nhãn Shader Engine ( SE ), trong khi Nvidia gọi chúng là Graphics Processing Clusters ( GPC ) – tên khác nhau nhưng cùng một vai trò .

Lý do cho sự phân vùng này của chip rất đơn thuần : những đơn vị chức năng giải quyết và xử lý lệnh không hề giải quyết và xử lý mọi thứ, vì nó sẽ quá lớn và phức tạp. Vì vậy, nó là hài hòa và hợp lý để đẩy 1 số ít trách nhiệm lên lịch và tổ chức triển khai xuống dòng. Điều đó cũng có nghĩa là mỗi phân vùng tách biệt hoàn toàn có thể thực thi một điều gì đó trọn vẹn độc lập với những phân vùng khác – thế cho nên một người hoàn toàn có thể giải quyết và xử lý một loạt những trình tạo bóng đồ họa, trong khi những phân vùng khác đang nghiền ngẫm những trình tạo bóng máy tính phức tạp và dài .
Trong trường hợp của RDNA 2, mỗi SE chứa một tập hợp những đơn vị chức năng công dụng cố định và thắt chặt của riêng nó : những mạch được phong cách thiết kế để triển khai một trách nhiệm đơn cử, mà thường lập trình viên không hề kiểm soát và điều chỉnh nhiều .
- Đơn vị thiết lập bắt đầu – chuẩn bị sẵn sàng những đỉnh để giải quyết và xử lý, cũng như tạo thêm ( tessellation ) và giải quyết và xử lý chúng
- Rasterizer – quy đổi thế giới hình tam giác 3D thành một lưới px 2D
- Kết xuất đầu ra ( ROP ) – đọc, ghi và tích hợp những px
Đơn vị thiết lập khởi đầu chạy với vận tốc 1 hình tam giác trên mỗi chu kỳ luân hồi đồng hồ đeo tay. Điều này có vẻ như không giống lắm nhưng đừng quên rằng những con chip này đang chạy ở bất kể đâu trong khoảng chừng từ 1,8 đến 2,2 GHz, vì thế thiết lập sơ khai sẽ không khi nào là một nút thắt cổ chai cho GPU. Đối với Ampere, đơn vị chức năng nguyên thủy được tìm thấy trong cấp tổ chức triển khai tiếp theo và tôi sẽ trình diễn ngay sau đây .
Cả AMD và Nvidia đều không nói quá nhiều về nó. Loại thứ hai với tên gọi Raster Engines, tất cả chúng ta biết rằng chúng giải quyết và xử lý 1 hình tam giác trên mỗi chu kỳ luân hồi đồng hồ đeo tay và tạo ra px, nhưng không có thêm thông tin nào để giải quyết và xử lý, ví dụ điển hình như độ đúng chuẩn px phụ của chúng .
Mỗi SE trong chip Navi 21 có 4 bộ 8 ROP, dẫn đến tổng số 128 đơn vị chức năng kết xuất hiển thị ; GA102 của Nvidia có 2 bộ 8 ROP trên mỗi GPC, vì thế chip khá đầy đủ có 112 đơn vị chức năng. Điều này có vẻ như như AMD có lợi thế ở đây, vì nhiều ROP hơn có nghĩa là nhiều px hơn hoàn toàn có thể được giải quyết và xử lý trên mỗi xung nhịp. Nhưng những đơn vị chức năng như vậy cần truy vấn tốt vào bộ nhớ đệm và bộ nhớ cục bộ, và tôi sẽ nói thêm về điều đó ở phần sau của bài viết này. Bây giờ, tất cả chúng ta hãy liên tục xem xét cách phân vùng SE / GPC được chia nhỏ hơn .
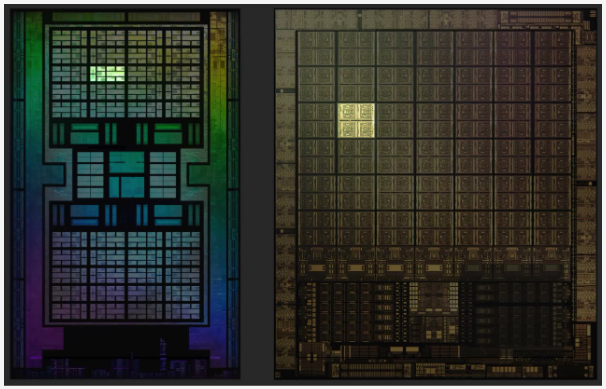
Các công cụ Shader của AMD được phân vùng phụ theo tên gọi là Đơn vị thống kê giám sát kép ( DCU ), với chip Navi 21 phân phối mười DCU cho mỗi SE – quan tâm rằng trong 1 số ít tài liệu, chúng cũng được phân loại là Bộ giải quyết và xử lý nhóm thao tác ( WGP ). Trong trường hợp của Ampere và GA102, chúng được gọi là Cụm giải quyết và xử lý cấu trúc ( TPC ), với mỗi GPU chứa 6 TPC. Mỗi cụm trong phong cách thiết kế của Nvidia đều chứa một thứ gọi là Polymorph Engine – về cơ bản, những đơn vị chức năng thiết lập khởi đầu của Ampere .
Chúng cũng chạy với vận tốc 1 tam giác mỗi xung nhịp và mặc dầu GPU của Nvidia có xung nhịp thấp hơn AMD, chúng có nhiều TPC hơn Navi 21 có SE. Vì vậy, với cùng một vận tốc xung nhịp, GA102 sẽ có một lợi thế đáng quan tâm là chip hoàn hảo chứa 42 đơn vị chức năng thiết lập shader, trong khi RDNA 2 mới của AMD chỉ có 4. mạng lưới hệ thống của Navi 21 ‘ s bốn. Vì cái thứ hai không có vận tốc cao hơn 75 % so với cái trước, có vẻ như như Nvidia là người đứng vị trí số 1 ở đây, khi nói đến việc giải quyết và xử lý hình học ( mặc dầu không có tựa game nào hoàn toàn có thể bị số lượng giới hạn trong nghành này ) .
Cấp ở đầu cuối của tổ chức triển khai chip là Đơn vị giám sát ( CU ) trong RDNA 2 và Bộ giải quyết và xử lý đa luồng ( SM ) trong Ampere – dây chuyền sản xuất sản xuất của những xí nghiệp sản xuất GPU .

Đây là những thứ rất giống rau củ trong chiếc bánh GPU, vì chúng chứa tổng thể những đơn vị chức năng có năng lực lập trình cao được sử dụng để giải quyết và xử lý đồ họa máy tính và giờ đây là trình tạo bóng theo dõi tracing shaders. Như bạn hoàn toàn có thể thấy trong hình trên, mỗi cái chiếm một phần rất nhỏ của khoảng trống khuôn toàn diện và tổng thể, nhưng chúng vẫn cực kỳ phức tạp và rất quan trọng so với hiệu suất tổng thể và toàn diện của chip .
Cho đến nay, chưa có bất kể sự phá vỡ thỏa thuận hợp tác nào nghiêm trọng, khi nói đến cách mọi thứ được sắp xếp và tổ chức triển khai trong hai GPU – danh pháp tổng thể đều khác nhau, nhưng tính năng của chúng thì giống nhau. Và chính bới phần đông những gì họ làm bị số lượng giới hạn bởi năng lực lập trình và tính linh động, nên bất kể lợi thế nào của cái này hơn cái kia, chỉ thuộc về quy mô, tức là cái nào có nhiều thứ đơn cử nhất đó .
Nhưng với CU và SM, AMD và Nvidia có những cách tiếp cận khác nhau về cách giải quyết và xử lý shader. Trong một số ít nghành, chúng có rất nhiều điểm chung, nhưng có rất nhiều điểm khác không phải như vậy .
Đếm số lõi theo cách Nvidia
Vì Ampere đã mạo hiểm trước RDNA 2, tất cả chúng ta sẽ xem xét những SM của Nvidia trước. Bây giờ không có ích gì khi xem hình ảnh của những thứ đã chết, vì chúng không hề cho tất cả chúng ta biết đúng chuẩn những gì bên trong chúng, thế cho nên hãy sử dụng sơ đồ tổ chức triển khai. Chúng không được cho là đại diện thay mặt cho cách những thành phần khác nhau được sắp xếp vật lý trong chip, chỉ là số lượng mỗi loại hiện hữu .
Trong đó Turing là một đổi khác đáng kể so với người nhiệm kỳ trước đó Pascal trên máy tính để bàn của nó ( mất đi một đống đơn vị chức năng FP64 và thanh ghi, nhưng có được lõi tensor và raytracing ), Ampere thực sự là một bản update khá nhẹ – tối thiểu là trên mệnh giá. Tuy nhiên, theo như bộ phận tiếp thị của Nvidia, phong cách thiết kế mới đã tăng gấp đôi số lượng lõi CUDA trong mỗi SM .
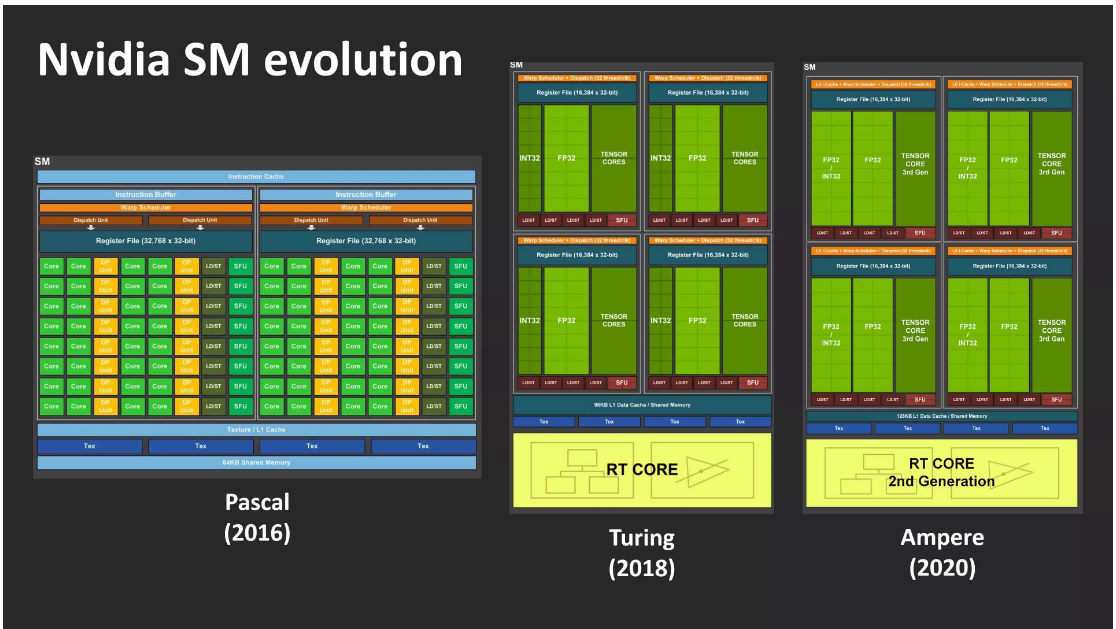
Trong Turing, Bộ giải quyết và xử lý đa luồng chứa bốn phân vùng ( nhiều lúc được gọi là khối giải quyết và xử lý ), trong đó mỗi đơn vị chức năng logic 16 x INT32 và 16 x FP32. Các mạch này được phong cách thiết kế để triển khai những phép toán rất đơn cử trên những giá trị tài liệu 32 – bit : đơn vị chức năng INT xử lý số nguyên và đơn vị chức năng FP hoạt động giải trí trên dấu phẩy động, tức là số thập phân, số .
Nvidia công bố rằng Ampere SM có tổng số 128 lõi CUDA, nhưng nói một cách trang nghiêm, điều này không đúng – hoặc nếu tất cả chúng ta phải bám vào số lượng này, thì Turing cũng vậy. Các đơn vị chức năng INT32 trong chip đó thực sự hoàn toàn có thể giải quyết và xử lý những giá trị float, nhưng chỉ trong 1 số ít rất nhỏ những thao tác đơn thuần. Đối với Ampere, Nvidia đã mở khoanh vùng phạm vi hoạt động giải trí toán học dấu phẩy động mà họ tương hỗ để khớp với những đơn vị chức năng FP32 khác. Điều đó có nghĩa là tổng số lõi CUDA trên mỗi SM không thực sự đổi khác ; chỉ là một nửa trong số họ hiện có nhiều năng lực hơn .
Tất cả những lõi trong mỗi phân vùng SM giải quyết và xử lý cùng một lệnh tại cùng một thời gian, nhưng vì những đơn vị chức năng INT / FP hoàn toàn có thể hoạt động giải trí độc lập, Ampere SM hoàn toàn có thể giải quyết và xử lý những phép tính lên đến 128 x FP32 mỗi chu kỳ luân hồi hoặc hoạt động giải trí 64 x FP32 và 64 x INT32 cùng nhau. Trong Turing, nó chỉ là cái sau .
Vì vậy, GPU mới có năng lực tăng gấp đôi sản lượng FP32 so với người nhiệm kỳ trước đó của nó. Đối với khối lượng việc làm thống kê giám sát, đặc biệt quan trọng là trong những ứng dụng chuyên nghiệp, đây là một bước tiến lớn ; nhưng so với chơi game, quyền lợi sẽ không có nhiều. Điều này được biểu lộ rõ khi tôi lần tiên phong thử nghiệm GeForce RTX 3080, sử dụng chip GA102 với 68 SMs được kích hoạt .

Mặc dù có thông lượng FP32 cao nhất 121 % so với GeForce 2080 Ti, nhưng vận tốc khung hình chỉ tăng trung bình 31 %. Vậy tại sao tổng thể sức mạnh giám sát đó lại bị tiêu tốn lãng phí ? Câu vấn đáp đơn thuần là không phải vậy, nhưng những tựa game không phải khi nào cũng chạy hướng dẫn FP32 .
Khi Nvidia phát hành Turing vào năm 2018, họ đã chỉ ra rằng trung bình khoảng chừng 36 % những lệnh được giải quyết và xử lý bởi GPU tương quan đến những tiến trình INT32. Các thống kê giám sát này thường được chạy để tìm ra địa chỉ bộ nhớ, so sánh giữa hai giá trị và luồng / điều khiển và tinh chỉnh logic .

Vì vậy, so với những hoạt động giải trí đó, tính năng FP32 tỷ suất kép không phát huy tính năng, vì những đơn vị chức năng có hai đường dẫn tài liệu chỉ hoàn toàn có thể triển khai số nguyên hoặc dấu phẩy động. Và một phân vùng SM sẽ chỉ chuyển sang chính sách này nếu tổng thể 32 luồng, đang được nó giải quyết và xử lý tại thời gian đó, có cùng hoạt động giải trí FP32 được xếp hàng để được giải quyết và xử lý. Trong toàn bộ những trường hợp khác, những phân vùng trong Ampere hoạt động giải trí giống như trong Turing .
Điều này có nghĩa là GeForce RTX 3080 chỉ có lợi thế FP32 11 % so với 2080 Ti, khi hoạt động giải trí ở chính sách INT + FP. Đây là nguyên do tại sao mức tăng hiệu suất thực tiễn khi chơi game không cao như những số liệu thô cho thấy nó phải như vậy .
Các nâng cấp cải tiến khác ? Có ít lõi Tensor hơn trên mỗi phân vùng SM, nhưng mỗi lõi có năng lực hơn nhiều so với lõi trong Turing. Các mạch này thực thi một phép tính rất đơn cử ( ví dụ điển hình như nhân hai giá trị FP16 và tích góp câu vấn đáp với 1 số ít FP16 khác ) và mỗi lõi hiện triển khai 32 hoạt động giải trí này trong mỗi chu kỳ luân hồi .
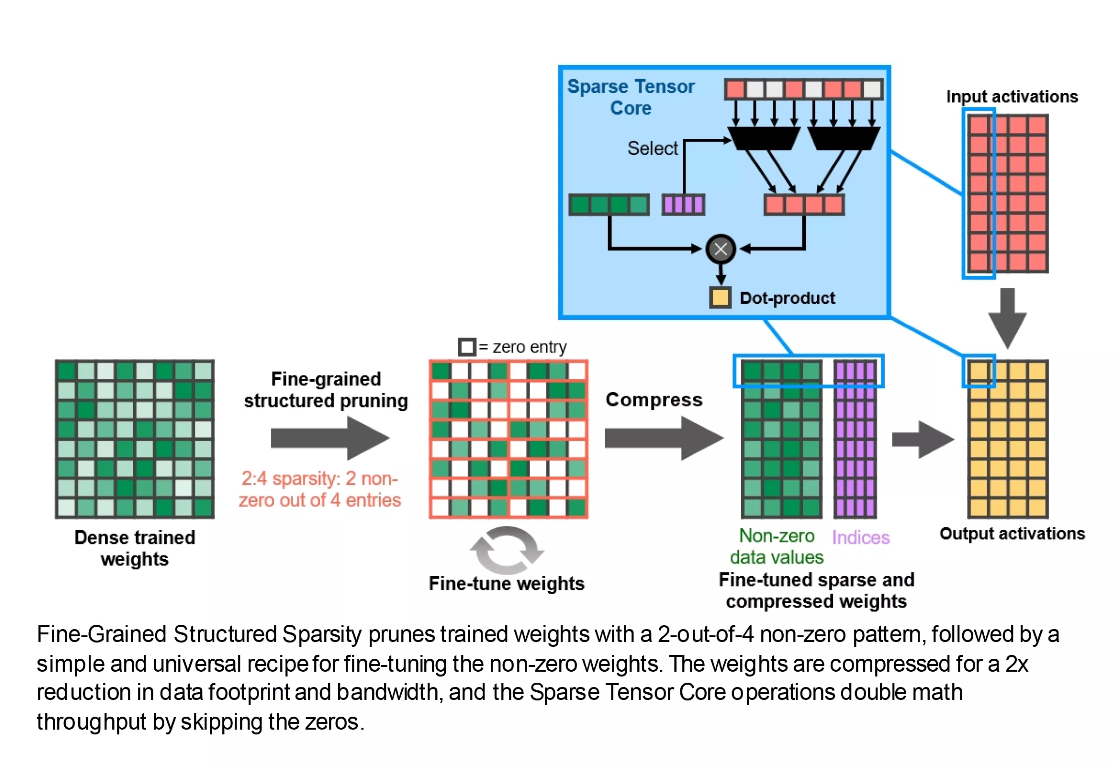
Họ cũng tương hỗ một tính năng mới được gọi là Fine-Grained Structured Sparsity và không đi sâu vào cụ thể của toàn bộ, về cơ bản, điều đó có nghĩa là tỷ suất toán học hoàn toàn có thể tăng gấp đôi, bằng cách lược bỏ tài liệu không tác động ảnh hưởng đến câu vấn đáp. Một lần nữa, đây là tin tốt cho những chuyên viên thao tác với mạng nơ-ron và AI, nhưng hiện tại, không có quyền lợi đáng kể nào cho những nhà tăng trưởng game .
Các lõi săn lùng tia cũng đã được tinh chỉnh và điều khiển : giờ đây chúng hoàn toàn có thể hoạt động giải trí độc lập với những lõi CUDA, vì thế trong khi chúng thực thi phép toán giao điểm theo chiều ngang hoặc tia nguyên thủy BVH, phần còn lại của SM vẫn hoàn toàn có thể giải quyết và xử lý shader. Phần của RT Core giải quyết và xử lý việc kiểm tra xem một tia có giao với một nguyên thủy hay không cũng đã tăng gấp đôi hiệu suất .

RT Cores cũng có phần cứng bổ trợ để giúp vận dụng tính năng raytracing để làm mờ hoạt động, nhưng tính năng này hiện chỉ được hiển thị trải qua API Optix độc quyền của Nvidia .
Có những kiểm soát và điều chỉnh khác, nhưng cách tiếp cận tổng thể và toàn diện là một trong những sự tăng trưởng hài hòa và hợp lý và không thay đổi, thay vì một phong cách thiết kế mới. Nhưng do không có gì đặc biệt quan trọng sai với năng lực thô của Turing ngay từ đầu, nên không có gì kinh ngạc khi thấy điều này .
Vậy còn AMD – họ đã làm gì với những Đơn vị giám sát trong RDNA 2 ?
Raytracing tuyệt vời
Về mệnh giá, AMD không có nhiều biến hóa về những Đơn vị đo lường và thống kê – chúng vẫn chứa hai bộ gồm một đơn vị chức năng vectơ SIMD32, một đơn vị chức năng vô hướng SISD, những đơn vị chức năng cấu trúc và một chồng những bộ nhớ đệm khác nhau. Có 1 số ít đổi khác tương quan đến loại tài liệu và những phép toán tương quan mà chúng hoàn toàn có thể thực thi và chúng tôi sẽ nói thêm về những loại tài liệu đó ngay bên dưới. Thay đổi đáng chú ý quan tâm nhất so với người dùng nói chung là AMD hiện cung ứng năng lực tăng cường phần cứng cho những quy trình tiến độ đơn cử trong raytracing .
Phần này của CU triển khai kiểm tra giao điểm hình tia hoặc tia-tam giác – giống như những lõi RT trong Ampe. Tuy nhiên, phần sau cũng tăng cường những thuật toán truyền tải BVH, trong RDNA 2, điều này được thực thi trải qua bộ shader máy tính sử dụng đơn vị chức năng SIMD 32 .
Bất kể một trong những lõi shader có bao nhiêu lõi hay vận tốc xung nhịp của chúng cao đến mức nào, việc sử dụng những mạch tùy chỉnh được phong cách thiết kế để chỉ triển khai một việc làm sẽ luôn tốt hơn so với cách tiếp cận tổng quát. Đây là nguyên do tại sao GPU được ý tưởng ngay từ đầu : mọi thứ trong quốc tế dựng hình đều hoàn toàn có thể được triển khai bằng CPU, nhưng thực chất chung của chúng khiến chúng không tương thích với điều này .
Các đơn vị chức năng RA nằm bên cạnh những bộ giải quyết và xử lý cấu trúc, vì chúng thực sự là một phần của cùng một cấu trúc. Trở lại tháng 7 năm 2019, chúng tôi đã báo cáo giải trình về sự Open của một văn bằng bản quyền trí tuệ do AMD đệ trình chi tiết cụ thể bằng cách sử dụng giải pháp ‘ tích hợp ‘ để giải quyết và xử lý những thuật toán chính trong dò tia …
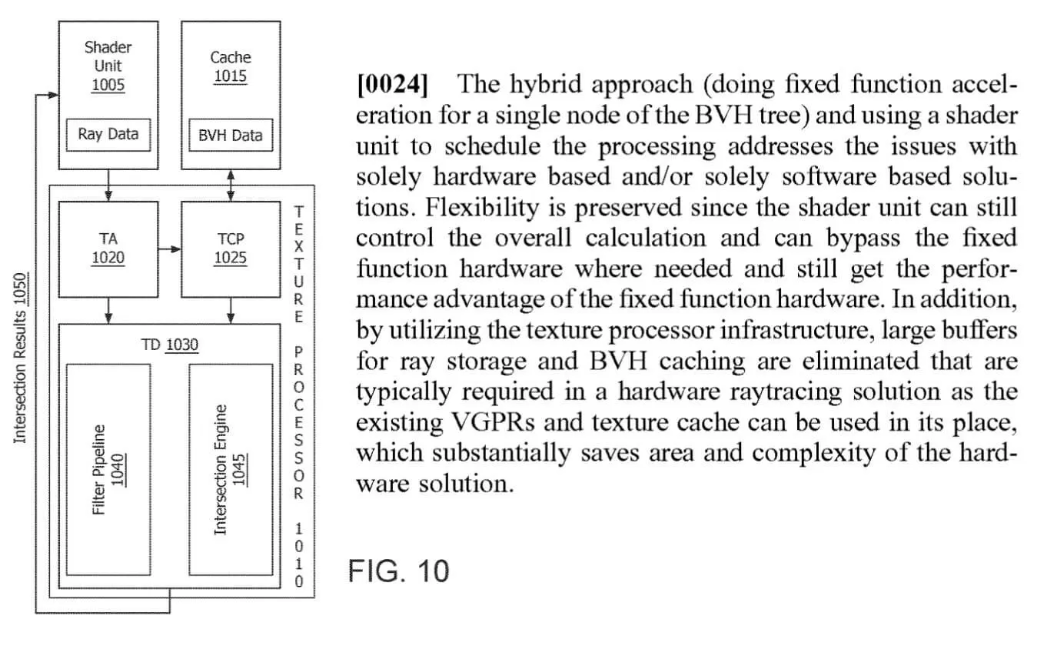
Mặc dù mạng lưới hệ thống này cung cấp tính linh động cao hơn và vô hiệu nhu yếu phải có những phần của khuôn không làm gì khi có khối lượng việc làm raytracing, việc tiến hành tiên phong của AMD về điều này có 1 số ít hạn chế. Điều đáng quan tâm nhất trong số đó là những bộ giải quyết và xử lý cấu trúc chỉ hoàn toàn có thể giải quyết và xử lý những hoạt động giải trí tương quan đến cấu trúc hoặc giao điểm nguyên thủy tia tại một thời gian bất kể .
Do RT Cores của Nvidia hiện hoạt động giải trí trọn vẹn độc lập với phần còn lại của SM, điều này có vẻ như mang lại cho Ampere một điểm đứng vị trí số 1 độc lạ so với RNDA 2, khi nói đến việc nghiền nát những cấu trúc tần suất và những bài kiểm tra giao điểm thiết yếu trong tracing .
Mặc dù tôi chỉ mới kiểm tra ngắn gọn hiệu suất raytracing trong những card đồ họa mới nhất của AMD, nhưng cho đến nay, tôi đã phát hiện ra rằng tác động ảnh hưởng của việc sử dụng tính năng raytracing phụ thuộc vào rất nhiều vào tựa game đang chơi .
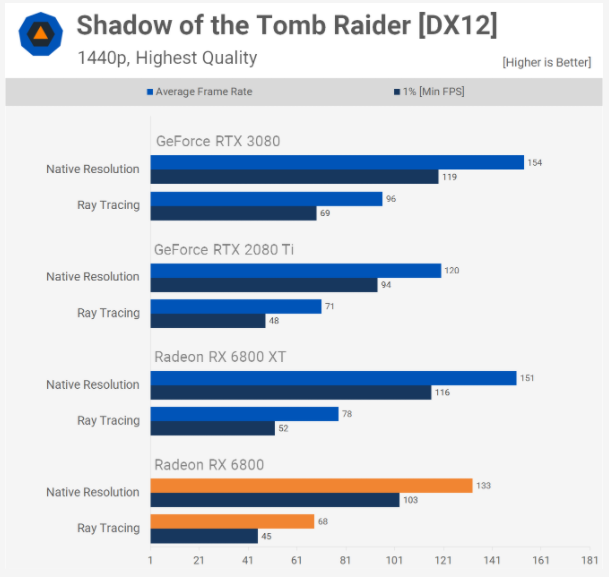
Ví dụ : trong Gears 5, Radeon RX 6800 ( sử dụng biến thể 60 CU của GPU Navi 21 ) chỉ đạt được 17 % vận tốc khung hình, trong khi trong Shadow of the Tomb Raider, số lượng này tăng lên mức mất trung bình 52 %. Trong khi đó, RTX 3080 của Nvidia ( sử dụng 68 SM GA102 ) có tỷ suất khung hình trung bình lần lượt là 23 % và 40 % trong hai tựa game .
Cần có một nghiên cứu và phân tích cụ thể hơn về raytracing để nói thêm bất kỳ điều gì về việc tiến hành của AMD, nhưng là lần tái diễn tiên phong của công nghệ tiên tiến, nó có vẻ như cạnh tranh đối đầu nhưng nhạy cảm với ứng dụng nào đang thực thi raytracing .
Như đã đề cập trước đây, những Đơn vị Máy tính trong RDNA 2 hiện tương hỗ nhiều kiểu tài liệu hơn ; đáng quan tâm nhất là những loại tài liệu có độ đúng chuẩn thấp như INT4 và INT8. Chúng được sử dụng cho những hoạt động giải trí tensor trong thuật toán học máy và trong khi AMD có kiến trúc riêng không liên quan gì đến nhau ( CDNA ) cho AI và TT tài liệu, bản update này được sử dụng với DirectML .
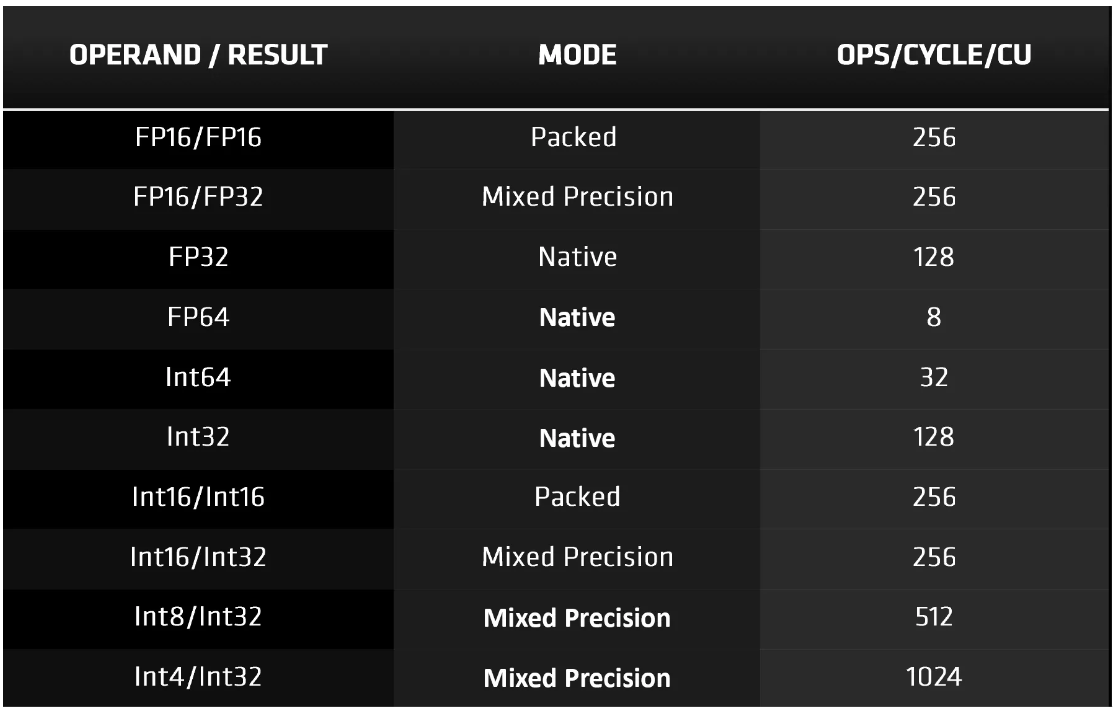
API này là một bổ trợ gần đây cho DirectX 12 của Microsoft và sự phối hợp giữa phần cứng và ứng dụng sẽ cung ứng năng lực tăng cường tốt hơn cho việc khử nhiễu trong những thuật toán dò tìm tia và tăng cấp theo thời hạn. Trong trường hợp thứ hai, tất yếu Nvidia có DLSS của riêng họ. Hệ thống của họ sử dụng những lõi Tensor trong SM để thực thi một phần đo lường và thống kê, nhưng do một quy trình tiến độ tựa như hoàn toàn có thể được thiết kế xây dựng trải qua DirectML, có vẻ như như những đơn vị chức năng này hơi thừa. Tuy nhiên, trong cả Turing và Ampere, Tensor Cores cũng giải quyết và xử lý tổng thể những phép toán tương quan đến những định dạng tài liệu FP16 .
Với RDNA 2, những thống kê giám sát như vậy được thực thi bằng cách sử dụng những đơn vị chức năng shader, sử dụng những định dạng tài liệu đóng gói, tức là mỗi thanh ghi vectơ 32 bit chứa hai thanh ghi 16 bit. Vậy cách tiếp cận nào tốt hơn ? AMD gắn nhãn những đơn vị chức năng SIMD32 của họ là bộ giải quyết và xử lý vectơ, vì chúng phát hành một lệnh cho nhiều giá trị tài liệu .
Mỗi đơn vị chức năng vectơ chứa 32 Bộ giải quyết và xử lý luồng và vì mỗi Bộ giải quyết và xử lý trong số này chỉ hoạt động giải trí trên một phần tài liệu duy nhất nên bản thân những hoạt động giải trí trong thực tiễn có thực chất là vô hướng. Điều này về cơ bản giống như một phân vùng SM trong Ampere, trong đó mỗi khối giải quyết và xử lý cũng mang một lệnh trên 32 giá trị tài liệu .
Nhưng trong đó hàng loạt SM trong phong cách thiết kế của Nvidia hoàn toàn có thể giải quyết và xử lý tới 128 phép tính FP32 FMA mỗi chu kỳ luân hồi ( hợp nhất nhân-cộng ), thì một Đơn vị đo lường và thống kê RDNA 2 chỉ triển khai được 64. Sử dụng FP16 tăng điều này lên 128 FMA mỗi chu kỳ luân hồi, giống Các lõi Tensor của Ampere khi thực thi phép toán FP16 tiêu chuẩn .
Các SM của Nvidia hoàn toàn có thể giải quyết và xử lý những lệnh để giải quyết và xử lý những giá trị số nguyên và số float cùng một lúc ( ví dụ : 64 FP32 và 64 INT32 ), đồng thời có những đơn vị chức năng độc lập cho những hoạt động giải trí FP16, thống kê giám sát tensor và tiến trình tracing. Các CU của AMD thực thi phần nhiều khối lượng việc làm trên những đơn vị chức năng SIMD32, mặc dầu chúng có những đơn vị chức năng vô hướng riêng không liên quan gì đến nhau tương hỗ phép toán số nguyên đơn thuần .
Source: https://vh2.com.vn
Category : Điện Tử

16 bài tập trắc nghiệm Dòng điện trong chân có đáp án chi tiết Với 16 bài tập trắc nghiệm Dòng điện trong chân có giải thuật cụ thể sẽ...

Bạn đang xem bài viết ✅ ✅ tại website Pgdphurieng. edu.vn hoàn toàn có thể kéo xuống dưới để đọc từng phần hoặc nhấn nhanh vào phần mục lục để...
Bài tập xác định chiều dòng điện cảm ứng và cách giải (hay, chi tiết) Bài tập xác định chiều dòng điện cảm ứng và cách giải Với Bài tập...

Máy biến dòng là một thiết bị điện – điện tử có vai trò không hề thiếu được trong mạng lưới hệ thống giám sát, thống kê giám sát điện...