Simulacrum, từ simulacrum Latin, là một sự bắt chước, giả mạo hoặc hư cấu. Khái niệm này được liên kết với mô phỏng, đó là hành động mô phỏng .Một...
Lập trình hàm – Wikipedia tiếng Việt
Trong ngành khoa học máy tính, lập trình hàm là một mô hình lập trình xem việc tính toán là sự đánh giá các hàm toán học và tránh sử dụng trạng thái và các dữ liệu biến đổi. Lập trình hàm nhấn mạnh việc ứng dụng hàm số, trái với phong cách lập trình mệnh lệnh, nhấn mạnh vào sự thay đổi trạng thái.[1] Lập trình hàm xuất phát từ phép tính lambda, một hệ thống hình thức được phát triển vào những năm 1930 để nghiên cứu định nghĩa hàm số, ứng dụng của hàm số, và đệ quy. Nhiều ngôn ngữ lập trình hàm có thể được xem là những cách phát triển giải tích lambda.[1]
Trong thực tế, sự khác biệt giữa hàm số toán học và cách dùng từ “hàm” trong lập trình mệnh lệnh đó là các hàm mệnh lệnh có thể tạo ra hiệu ứng lề, làm thay đổi giá trị của một phép tính trước đó. Vì vậy các hàm kiểu này thiếu tính trong suốt tham chiếu, có nghĩa là cùng một biểu thức ngôn ngữ lại có thể tạo ra nhiều giá trị khác nhau vào các thời điểm khác nhau tùy thuộc vào trạng thái của chương trình đang thực thi. Ngược lại, trong lập trình hàm, giá trị xuất ra của một hàm chỉ phụ thuộc vào các tham số đầu vào của hàm, vì thế gọi hàm f hai lần với cùng giá trị tham số x sẽ cho ra cùng kết quả f(x). Việc loại bỏ hiệu ứng lề có thể làm cho chương trình dễ hiểu hơn rất nhiều và người ta có dự đoán được hành vi của một chương trình, đó chính là một trong các động lực chính cho sự phát triển của lập trình hàm.[1]
Các ngôn ngữ lập trình hàm, đặc biệt là các loại thuần lập trình hàm, có ảnh hưởng lớn trong giới học thuật hơn là dùng để phát triển các phần mềm thương mại. Tuy vậy, các ngôn ngữ lập trình hàm nổi bật như Scheme,[2][3][4][5] Erlang,[6][7][8] Objective Caml,[9][10]
và Haskell[11][12] đã được nhiều tổ chức khác nhau sử dụng trong các ứng dụng công nghiệp và thương mại. Lập trình hàm cũng được sử dụng trong công nghiệp thông qua các ngôn ngữ lập trình chuyên biệt như R (thống kê),[13][14] Mathematica (toán học hình thức),[15] J và K (phân tích tài chính)[cần dẫn nguồn], F# trong Microsoft.NET và XSLT (XML).[16][17] Các ngôn ngữ chuyên biệt dạng khai báo được sử dụng rộng rãi hiện nay như SQL và Lex/Yacc, cũng sử dụng một số thành phần của lập trình hàm, đặc biệt để tránh các giá trị biến đổi.[18] Các bảng tính (spreadsheet) cũng có thể được xem là các ngôn ngữ lập trình hàm.[19]
Lập trình theo phong cách lập trình hàm cũng có thể thực hiện ở các ngôn ngữ không được thiết kế riêng cho lập trình hàm. Ví dụ, ngôn ngữ lập trình mệnh lệnh Perl đã có một cuốn sách viết về cách áp dụng các khái niệm lập trình hàm vào đó.[20] JavaScript, một trong các ngôn ngữ được dùng nhiều hiện nay, có khả năng lập trình hàm.[21]
Bạn đang đọc: Lập trình hàm – Wikipedia tiếng Việt
Các khái niệm[sửa|sửa mã nguồn]
Một số khái niệm và quy mô chỉ có ở lập trình hàm, và thường lạ lẫm với kiểu lập trình mệnh lệnh ( gồm có cả lập trình hướng đối tượng người dùng ). Tuy nhiên, những ngôn từ lập trình thường lai tạp nhiều hình thái lập trình khác nhau để lập trình viên sử dụng những ngôn từ ” mệnh lệnh nhất ” cũng hoàn toàn có thể tận dụng một số ít những khái niệm này. [ 22 ]
Hàm hạng nhất và hàm bậc cao[sửa|sửa mã nguồn]
Hàm bậc cao là các hàm số hoặc có thể nhận các hàm số khác làm tham số hoặc có thể trả về kết quả là hàm số (phép toán vi phân
d
/
d
x
{\displaystyle d/dx}

f
{\displaystyle f}

Các hàm bậc cao có liên hệ ngặt nghèo với hàm hạng nhất, ở chỗ những hàm bậc cao và hàm hạng nhất đều được cho phép nhận hàm số làm tham số và trả về những hàm khác. Sự độc lạ giữa hai loại này rất mờ nhạt : ” bậc cao ” miêu tả một khái niệm hàm trong toán học thống kê giám sát trong những hàm khác, còn ” hàm hạng nhất ” là một thuật ngữ của ngành khoa học máy tính miêu tả những thực thể của ngôn từ lập trình trong đó không có số lượng giới hạn về việc sử dụng ( thế cho nên những hàm hạng nhất hoàn toàn có thể Open ở bất kỳ đâu trong chương trình, giống như những thực thể hạng nhất khác nhau số lượng, trong đó có cả việc làm tham số cho những hàm khác và làm giá trị trả về của hàm khác ) .Các hàm bậc cao được cho phép vận dụng bán phần hoặc currying, một kỹ thuật trong đó hàm lần lượt sử dụng từng tham số của nó, mỗi lần sử dụng lại trả về một hàm mới và gật đầu tham số tiếp theo. Việc làm này được cho phép người lập trình màn biểu diễn một cách súc tích hàm số thừa kế, tựa như như toán tử cộng sẽ lần lượt cộng từng số tự nhiên lại với nhau .
Hàm thuần túy[sửa|sửa mã nguồn]
Các hàm ( hoặc biểu thức ) thuần túy hàm không có bộ nhớ hoặc những hiệu ứng lề nhập / xuất. Điều này có nghĩa là những hàm thuần túy có 1 số ít đặc tính có ích, mà đa phần trong chúng hoàn toàn có thể dùng để tối ưu mã nguồn :
- Nếu kết quả của một biểu thức thuần túy không được sử dụng, ta có thể xóa nó đi mà không ảnh hưởng đến các biểu thức khác.
- Nếu một hàm thuần túy được gọi cùng với các tham số không tạo ra hiệu ứng lề, kết quả sẽ là hằng số tương ứng với danh sách tham số cụ thể (có khi gọi là trong suốt tham chiếu), tức là hàm thuần túy nếu được gọi lần nữa với cùng bộ tham số, kết quả trả về cũng sẽ y hệt như trước (điều này cho phép tối ưu hóa lưu đệm như memoization).
- Nếu không có sự phụ thuộc về dữ liệu giữa hai biểu thức thuần túy, thì thứ tự của chúng có thể đảo cho nhau, hoặc chúng có thể thực hiện song song mà không ảnh hưởng đến nhau (hay nói cách khác, đánh giá một biểu thức thuần túy bất kỳ là an toàn về luồng (thread-safe)).
- Nếu toàn bộ ngôn ngữ không cho phép hiệu ứng lề, thì chiến thuật đánh giá hàm nào cũng dùng được; việc này trao cho trình biên dịch quyền tự do sắp xếp lại hoặc phối hợp việc đánh giá biểu thức trong một chương trình (ví dụ, dùng kỹ thuật loại bỏ cây).
Trong khi hầu hết trình biên dịch dành cho những ngôn từ lập trình mệnh lệnh hoàn toàn có thể nhận dạng hàm thuần túy, và triển khai những phép khử biểu thức con thường gặp trong những lệnh gọi hàm thuẫn túy, chúng không hề khi nào cũng làm như vậy so với những thư viện đã dịch sẵn, thường không bật mý thông tin này, vì vậy làm cản trở sự tối ưu hóa tương quan đến những hàm bên ngoài như vậy. Một số trình biên dịch, như gcc, thêm từ khóa bổ trợ để giúp lập trình viên ghi lại hàm nào là hàm thuần túy, để cho phép tối ưu hóa kiểu như vậy. Fortran 95 cho phép hàm được chỉ định ” thuần túy ” .
Vòng lặp trong những ngôn từ hàm thường được thực thi trải qua đệ quy. Hàm đệ quy sẽ tự gọi chính nó, được cho phép triển khai đi triển khai lại một tác vụ. Việc đệ quy hoàn toàn có thể yên cầu phải sử dụng một chồng ( stack ), nhưng đệ quy đuôi vẫn hoàn toàn có thể được trình biên dịch nhận ra và tối ưu hóa nó thành cùng đoạn mã được dùng để hiện thực vòng lặp trong ngôn từ mệnh lệnh. Tiêu chuẩn của ngôn từ Scheme là phải nhận diện và tối ưu hóa được đệ quy đuôi. Một trong những cách tối ưu hóa đệ quy đuôi là chuyển chương trình thành kiểu truyền liên tục trong quy trình dịch .Các mẫu đệ quy thông dụng đều hoàn toàn có thể được khử đệ quy bằng những hàm bậc cao, catamorphism và anamorphism ( hay ” fold ” và ” unfold ” – gấp và mở gấp ) là những ví dụ rõ nhất. Các hàm bậc cao như vậy đóng vai trò tương tự như như những cấu trúc điều khiển và tinh chỉnh có sẵn như vòng lặp trong ngôn từ mệnh lệnh .
Đa số các ngôn ngữ lập trình hàm đa mục đích đều cho phép đệ quy không giới hạn và là Turing complete, khiến cho bài toán dừng trở nên không quyết định được, có thể gây ra sự thiếu căn cứ cho việc suy diễn công thức, và nói chung đòi hỏi phải có khái niệm không nhất quán trong logic do hệ thống kiểu của ngôn ngữ quy định. Một vài ngôn ngữ lập trình với mục đích đặc biệt như Coq chỉ cho phép đệ quy well-founded và chuẩn hóa mạnh (tính toán không dừng chỉ có thể biểu diễn bằng dòng giá trị vô hạn gọi là codata). Kết quả là, những ngôn ngữ như vậy không phải Turing complete và một số hàm không thể biểu diễn trong ngôn ngữ, dù ngôn ngữ đó vẫn có thể biểu diễn được rất nhiều cách tính toán thú vị mà tránh được vấn đề do đệ quy không giới hạn gây ra. Lập trình hàm giới hạn trong việc đệ quy well-founded với một số ràng buộc khác được gọi là lập trình hàm hoàn toàn (total). Xem Turner 2004 để biết thêm.[23]
Tính toán chặt và không chặt[sửa|sửa mã nguồn]
Có thể chia các ngôn ngữ hàm làm hai loại tùy vào việc chúng sử dụng cách tính toán biểu thức chặt (tham lam) hay không chặt (lười biếng), là những khái niệm chỉ cách xử lý thông số của hàm khi tính toán một biểu thức. Sự khác biệt về các cách tính toán này xuất hiện ở ngữ nghĩa biểu thị của biểu thức khi chúng có chứa phép toán lỗi hoặc có vấn đề. Khi tính toán chặt, việc tính toán số hạng có chứa lỗi cũng sẽ dẫn đến lỗi. Ví dụ, biểu thức:
- print length([2+1, 3*2, 1/0, 5-4])
sẽ không tính được theo thống kê giám sát chặt vì phép chia không tại thành phần thứ ba của list. Còn với thống kê giám sát không chặt, hàm length sẽ trả về giá trị 4, vì khi thống kê giám sát hàm, nó không nỗ lực giám sát những thành phần trong list. Nói một cách ngắn gọn, giám sát chặt luôn luôn đo lường và thống kê tổng thể cấc số hạng của hàm trước khi giải quyết và xử lý hàm. Tính toán không chặt không giám sát tham số của hàm trừ khi nó cần giá trị đó để đo lường và thống kê hàm .Cách hiện thực thường thì của thống kê giám sát không chặt trong ngôn từ hàm là thu giảm đồ thị. Cách giám sát không chặt được dùng mặc định trong vài ngôn từ lập trình hàm thuần túy, như Miranda, Clean và Haskell .Hughes vào năm 1984 đã phản bác việc dùng thống kê giám sát không chặt làm chính sách để tăng tính module hóa của chương trình trải qua quy trình chia nhỏ bài toán, bằng cách làm cho việc hiện thực độc lập giữa nhà phân phối và người mua thuận tiện hơn. [ 24 ] Launchbury 1993 diễn đạt 1 số ít khó khăn vất vả mà nhìn nhận lười biếng tạo ra, đơn cử trong việc nghiên cứu và phân tích nhu yếu tàng trữ của chương trình, và đề xuất kiến nghị ngữ nghĩa hoạt động giải trí để tương hỗ cho việc nghiên cứu và phân tích này. [ 25 ] Harper 2009 đề xuất kiến nghị đưa cả thống kê giám sát chặt lẫn không chặt vào một ngôn từ, bằng cách dùng mạng lưới hệ thống kiểu của ngôn từ để phân biệt chúng. [ 26 ]
Hệ thống kiểu, tính đa hình, kiểu tài liệu đại số và so trùng mẫu[sửa|sửa mã nguồn]
Đặc biệt kể từ sự tăng trưởng của luận kiểu Hindley – Milner trong thập niên 1970, những ngôn từ lập trình hàm có khuynh hướng sử dụng phép tính lambda định kiểu, chống lại phép tính lambda bất định kiểu đã được dùng trong Lisp và những biến thể của nó ( như Scheme ). Việc sử dụng những kiểu tài liệu đại số và so trùng mẫu làm cho việc thao tác những cấu trúc tài liệu phức tạp trở nên thuận tiện và rõ ràng hơn ; sự sống sót của việc kiểm tra kiểu can đảm và mạnh mẽ trong thời hạn biên dịch làm cho những chương trình trở nên đáng đáng tin cậy hơn, trong khi đó luận kiểu giải phóng lập trình viên khỏi việc cần phải khai báo thủ công bằng tay những kiểu để biên dịch .Một số ngôn từ lập trình hàm khuynh hướng nghiên cứu và điều tra như Coq, Agda, Cayenne, và Epigram dựa trên triết lý kiểu intuitionistic, thuyết này được cho phép những kiểu phụ thuộc vào vào những term. Các kiểu như vậy được gọi là những kiểu phụ thuộc vào. Các mạng lưới hệ thống kiểu này không có những luận kiểu khả định và rất khó để hiểu và lập trình với chúng. Nhưng những kiểu phụ thuộc vào này hoàn toàn có thể miêu tả những mệnh đề tự do trong logic mệnh đề. Thông qua Curry – Howard isomorphism, sau đó, những chương trình định kiểu tốt trong những ngôn từ này sẽ trở thành những phương tiện đi lại cho việc viết những chứng tỏ toán học hình thức mà từ đó một trình biên dịch hoàn toàn có thể sinh ra mã được ghi nhận. Trong khi những ngôn từ này hầu hết được chăm sóc trong nghiên cứu và điều tra học thuật ( kể cả trong toán học hình thức hóa ), chúng cũng mở màn được sử dụng trong kĩ thuật. Compcert là một trình biên dịch cho một tập con của ngôn từ lập trình C được viết bằng Coq và đã được xác nhận chính thức. [ 27 ]Một dạng số lượng giới hạn của những kiểu phụ thuộc vào được gọi là kiểu tài liệu đại số được khái quát hóa ( GADT ). Dạng này hoàn toàn có thể được thực thi theo cách cung ứng một vài trong số những quyền lợi của lập trình phụ thuộc vào kiểu trong khi tránh hầu hết sự phiền phức của nó. [ 28 ] GADT có sẵn trong Trình biên dịch Glasgow Haskell và trong Scala ( như ” case classes ” ), và được cho là phần bổ trợ vào những ngôn từ khác gồm có cả Java và C #. [ 29 ]
Lập trình hàm trong những ngôn từ phi hàm[sửa|sửa mã nguồn]
Có thể sử dụng phong cách hàm của việc lập trình trong các ngôn ngữ mà theo truyền thống không được xem là ngôn ngữ hàm.[30] Một số ngôn ngữ phi hàm đã mượn nhiều đặc điểm như các hàm bậc cao hơn, và các quan niệm danh sách từ các ngôn ngữ lập trình hàm. Điều này làm cho việc chấp nhận phong cách hàm dễ dàng hơn khi sử dụng những ngôn ngữ này. Các cấu trúc hàm như các “hàm bậc cao hơn” và các “danh sách lười” có thể lấy được trong C++ qua các thư viện.[31] Trong C, các con trỏ hàm có thể được dùng để đạt được một vài trong số các hiệu quả của các hàm bậc cao hơn. Ví dụ hàm chung map có thể được thực thi bằng cách dùng các con trỏ hàm. Trong Visual Basic 9 và C# 3.0 và cao hơn, các hàm lambda có thể được dùng để viết các chương trình theo phong cách hàm.
[32]
Trong Java, các lớp nặc danh đôi khi được sử dụng để mô phỏng các sự đóng,[cần dẫn nguồn] tuy nhiên các lớp nặc danh không phải luôn luôn là các thay thế chính xác cho các sự đóng bởi vì chúng có nhiều khả năng bị hạn chế hơn.
Nhiều mẫu thiết kế hướng đối tượng có thể biểu đạt bằng các thuật ngữ lập trình hàm: ví dụ, mẫu chiến lược đơn giản chỉ ra cách dùng của hàm bậc cao hơn, và mẫu khách viếng thăm gần như tương ứng với một catamorphism, hoặc fold.
Các ích lợi của tài liệu không bao giờ thay đổi hoàn toàn có thể được thấy ngay cả trong những chương trình mệnh lệnh, vì vậy những lập trình viên tiếp tục cố gắng nỗ lực làm cho một số ít tài liệu không bao giờ thay đổi ngay cả trong những chương trình mệnh lệnh. [ 33 ]
Liên kết ngoài[sửa|sửa mã nguồn]
Source: https://vh2.com.vn
Category : Tin Học

Khởi động sao tam giác là một trong số những phương pháp để khởi động động cơ đơn giản, hiệu quả và tiết kiệm chi phí. Vậy Khởi động sao...
Đồ Án 2: Thiết kế mạch Buck Converter DC-DC Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây...
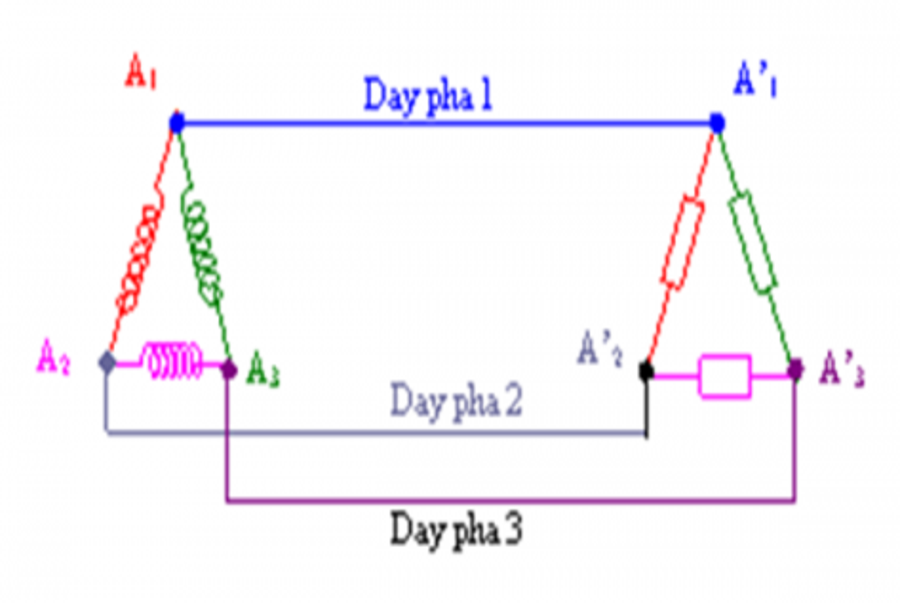
Nguyên tắc hoạt động máy phát điện xoay chiềuDựa trên hiện tượng cảm ứng điện từ: Khi từ thông qua một vòng dây biến thiên điều hòa, trong vòng dây...
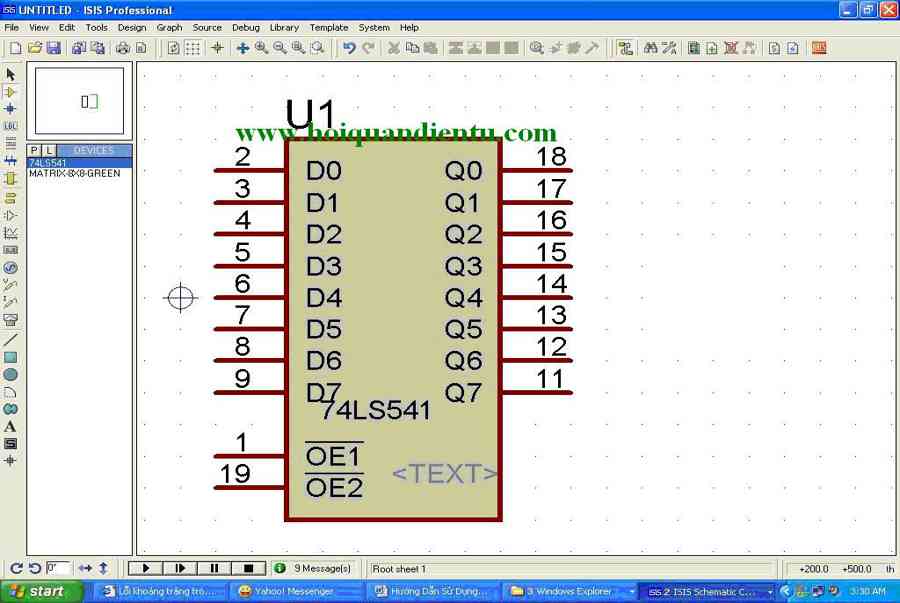
HDSD Led matrix Trong Proteus Và Cách Quét LED SD 8051 ( 8 x 64 ) Ngày 03/08/2010 20:19:50 / Lượt xem: 27279 / Người đăng: biendt / Nguồn: [email protected]...