Simulacrum, từ simulacrum Latin, là một sự bắt chước, giả mạo hoặc hư cấu. Khái niệm này được liên kết với mô phỏng, đó là hành động mô phỏng .Một...
Ngôn ngữ lập trình – Wikipedia tiếng Việt
Ngôn ngữ lập trình là ngôn ngữ hình thức bao gồm một tập hợp các lệnh tạo ra nhiều loại đầu ra khác nhau. Ngôn ngữ lập trình được sử dụng trong lập trình máy tính để thực hiện các thuật toán.
Hầu hết những ngôn ngữ lập trình bao gồm những lệnh cho máy tính. Có những máy lập trình sử dụng một tập hợp những lệnh đơn cử, thay vì những ngôn ngữ lập trình chung chung. Kể từ đầu những năm 1800, những chương trình đã được sử dụng để khuynh hướng hoạt động giải trí của máy móc như khung dệt Jacquard, hộp nhạc và đàn piano cơ. [ 1 ] Các chương trình cho những máy này ( ví dụ điển hình như cuộn giấy của đàn piano ) không tạo ra những hành vi khác nhau để cung ứng với những đầu vào hoặc điều kiện kèm theo khác nhau .
Hàng nghìn ngôn ngữ lập trình khác nhau đã được tạo ra và nhiều ngôn ngữ lập trình khác đang được tạo ra hàng năm. Nhiều ngôn ngữ lập trình được viết dưới dạng mệnh lệnh (tức là một chuỗi các thao tác phải thực hiện) trong khi các ngôn ngữ khác sử dụng dạng khai báo (tức là kết quả mong muốn được chỉ định chứ không phải cách thức làm ra nó).
Bạn đang đọc: Ngôn ngữ lập trình – Wikipedia tiếng Việt
Mô tả của một ngôn ngữ lập trình thường được chia thành hai thành phần cú pháp ( hình thức ) và ngữ nghĩa ( ý nghĩa ). Một số ngôn ngữ được xác lập bởi tài liệu đặc tả ( ví dụ : ngôn ngữ lập trình C được chỉ định bởi Tiêu chuẩn ISO ) trong khi những ngôn ngữ khác ( ví dụ điển hình như Perl ) có cách tiến hành chi phối được coi là tham chiếu. Một số ngôn ngữ có cả hai, với ngôn ngữ cơ bản được xác lập bởi một tiêu chuẩn và những phần lan rộng ra được lấy từ việc tiến hành chi phối là phổ cập .Lý thuyết ngôn ngữ lập trình là một nghành con của khoa học máy tính điều tra và nghiên cứu về phong cách thiết kế, sự thực thi, nghiên cứu và phân tích, đặc thù và phân loại của những ngôn ngữ lập trình .
Ngôn ngữ lập trình là một ký hiệu để viết chương trình, là những đặc tả của một phép tính hoặc thuật toán. [ 2 ] Một số tác giả hạn chế thuật ngữ ” ngôn ngữ lập trình ” so với những ngôn ngữ hoàn toàn có thể biểu lộ toàn bộ những thuật toán hoàn toàn có thể. [ 2 ] [ 3 ] Các đặc thù thường được coi là quan trọng so với những gì cấu thành một ngôn ngữ lập trình bao gồm :
Các ngôn ngữ ghi lại như XML, HTML hoặc troff, xác lập tài liệu có cấu trúc, thường không được coi là ngôn ngữ lập trình. [ 12 ] [ 13 ] [ 14 ] Tuy nhiên, ngôn ngữ lập trình hoàn toàn có thể san sẻ cú pháp với những ngôn ngữ lưu lại nếu ngữ nghĩa giám sát được xác lập. Ví dụ, XSLT là một ngôn ngữ hoàn hảo Turing hoàn toàn sử dụng cú pháp XML. [ 15 ] [ 16 ] [ 17 ] Hơn nữa, LaTeX, phần nhiều được sử dụng để cấu trúc tài liệu, cũng chứa một tập con hoàn hảo Turing. [ 18 ] [ 19 ]
Thuật ngữ ngôn ngữ máy tính đôi khi được sử dụng thay thế cho ngôn ngữ lập trình.[20] Tuy nhiên, cách sử dụng của cả hai thuật ngữ khác nhau giữa các tác giả, bao gồm cả phạm vi chính xác của mỗi thuật ngữ. Một cách sử dụng mô tả các ngôn ngữ lập trình như một tập hợp con của các ngôn ngữ máy tính.[21] Tương tự như vậy, các ngôn ngữ được sử dụng trong máy tính có mục tiêu khác với mục đích thể hiện các chương trình máy tính là các ngôn ngữ máy tính được chỉ định chung. Ví dụ, các ngôn ngữ đánh dấu đôi khi được gọi là ngôn ngữ máy tính để nhấn mạnh rằng chúng không được sử dụng để lập trình.[22]
Một cách sử dụng khác coi ngôn ngữ lập trình là cấu trúc kim chỉ nan để lập trình máy trừu tượng và ngôn ngữ máy tính là tập hợp con của chúng chạy trên máy tính vật lý có tài nguyên phần cứng hữu hạn. [ 23 ] John C. Reynolds nhấn mạnh vấn đề rằng những ngôn ngữ đặc tả hình thức cũng giống như những ngôn ngữ lập trình giống như những ngôn ngữ dùng để thực thi. Ông cũng lập luận rằng những định dạng nguồn vào văn bản và thậm chí còn đồ họa ảnh hưởng tác động đến hoạt động giải trí của máy tính là ngôn ngữ lập trình, mặc dầu thực tiễn là chúng thường không hoàn hảo và nhận xét rằng sự thiếu hiểu biết về những khái niệm ngôn ngữ lập trình là nguyên do dẫn đến nhiều sai sót trong những định dạng nguồn vào. [ 24 ]
Phát triển bắt đầu[sửa|sửa mã nguồn]
Các máy tính rất sơ khai, ví dụ điển hình như Colossus, được lập trình mà không cần sự trợ giúp của chương trình được tàng trữ, bằng cách sửa đổi mạch điện của chúng hoặc thiết lập những kho những rơ le tinh chỉnh và điều khiển vật lý .
Sau đó một chút, các chương trình có thể được viết bằng ngôn ngữ máy, trong đó lập trình viên viết từng lệnh dưới dạng số mà phần cứng có thể thực thi trực tiếp. Ví dụ: lệnh thêm giá trị vào hai vị trí bộ nhớ có thể bao gồm 3 số: một “mã opcode” chọn thao tác “cộng” và hai vị trí bộ nhớ. Các chương trình, ở dạng thập phân hoặc nhị phân, được đọc từ thẻ đục lỗ, băng giấy, băng từ hoặc được chuyển vào trên các công tắc trên bảng điều khiển phía trước của máy tính. Ngôn ngữ máy sau này được gọi là ngôn ngữ lập trình thế hệ thứ nhất (1GL).
Bước tiếp theo là sự phát triển của cái gọi là ngôn ngữ lập trình thế hệ thứ hai (2GL) hoặc hợp ngữ, những ngôn ngữ này vẫn được gắn chặt với kiến trúc tập lệnh của máy tính cụ thể. Những điều này phục vụ cho việc làm cho chương trình dễ đọc hơn nhiều và giúp người lập trình giảm bớt các tính toán địa chỉ tẻ nhạt và dễ xảy ra lỗi.
Các ngôn ngữ lập trình cấp cao đầu tiên, hoặc ngôn ngữ lập trình thế hệ thứ ba (3GL), được viết vào những năm 1950. Một ngôn ngữ lập trình cấp cao ban đầu được thiết kế cho máy tính là Plankalkül, được phát triển cho Z3 của Đức bởi Konrad Zuse từ năm 1943 đến năm 1945. Tuy nhiên, nó đã không được thực hiện cho đến năm 1998 và 2000.[25]
Mã ngắn của John Mauchly, được đề xuất kiến nghị vào năm 1949, là một trong những ngôn ngữ cấp cao tiên phong từng được tăng trưởng cho máy tính điện tử. [ 26 ] Không giống như mã máy, những câu lệnh mã ngắn trình diễn những biểu thức toán học ở dạng dễ hiểu. Tuy nhiên, chương trình phải được dịch sang mã máy mỗi khi nó chạy, làm cho quy trình chạy chậm hơn nhiều so với chạy mã máy tương tự .Tại Đại học Manchester, Alick Glennie đã tăng trưởng Autocode vào đầu những năm 1950. Là một ngôn ngữ lập trình, nó sử dụng một trình biên dịch để tự động hóa quy đổi ngôn ngữ thành mã máy. Mã và trình biên dịch tiên phong được tăng trưởng vào năm 1952 cho máy tính Mark 1 tại Đại học Manchester và được coi là ngôn ngữ lập trình cấp cao được biên dịch tiên phong. [ 27 ] [ 28 ]Mã tự động hóa thứ hai được RA Brooker tăng trưởng cho Mark 1 vào năm 1954 và được gọi là ” Mã tự động hóa Mark 1 “. Brooker cũng đã tăng trưởng một mã tự động hóa cho Ferranti Mercury vào những năm 1950 cùng với Đại học Manchester. Phiên bản cho EDSAC 2 được ý tưởng bởi DF Hartley của Phòng thí nghiệm Toán học Đại học Cambridge vào năm 1961. Được gọi là Mã tự động hóa EDSAC 2, nó là sự tăng trưởng trực tiếp từ Mã tự động hóa của Mercury được kiểm soát và điều chỉnh cho tương thích với thực trạng địa phương và được quan tâm vì năng lực tối ưu hóa mã đối tượng người tiêu dùng và chẩn đoán ngôn ngữ nguồn đã được nâng cấp cải tiến vào thời gian đó. Là một chuỗi tăng trưởng văn minh nhưng riêng không liên quan gì đến nhau, Atlas Autocode được tăng trưởng cho máy Atlas 1 của Đại học Manchester .Năm 1954, FORTRAN được John Backus ý tưởng ra tại IBM. Nó là ngôn ngữ lập trình mục tiêu chung cấp cao tiên phong được sử dụng thoáng đãng để có một tiến hành tính năng, thay vì chỉ là một phong cách thiết kế trên giấy. [ 29 ] [ 30 ] Nó vẫn là một ngôn ngữ thông dụng cho đo lường và thống kê hiệu suất cao [ 31 ] và được sử dụng cho những chương trình nhìn nhận và xếp hạng những siêu máy tính nhanh nhất quốc tế. [ 32 ]Một ngôn ngữ lập trình bắt đầu khác được ý tưởng bởi Grace Hopper ở Mỹ, được gọi là FLOW-MATIC. Nó được tăng trưởng cho UNIVAC I tại Remington Rand trong thời hạn từ năm 1955 đến năm 1959. Hopper nhận thấy rằng người mua giải quyết và xử lý tài liệu kinh doanh thương mại không tự do với ký hiệu toán học, và vào đầu năm 1955, bà và nhóm của mình đã viết một đặc tả cho một ngôn ngữ lập trình tiếng Anh và triển khai một nguyên mẫu. [ 33 ] Trình biên dịch FLOW-MATIC được công bố thoáng đãng vào đầu năm 1958 và về cơ bản hoàn thành xong vào năm 1959. [ 34 ] FLOW-MATIC có tác động ảnh hưởng lớn trong việc phong cách thiết kế COBOL, vì chỉ có nó và hậu duệ trực tiếp của nó là AIMACO được sử dụng trong thực tiễn vào thời gian đó. [ 35 ]
Đặc điểm chung của ngôn ngữ lập trình[sửa|sửa mã nguồn]
Mỗi ngôn ngữ lập trình hoàn toàn có thể được xem như thể một tập hợp của những chi tiết cụ thể kỹ thuật chú trọng đến cú pháp, từ vựng, và ý nghĩa của ngôn ngữ .Những chi tiết cụ thể kỹ thuật này thường bao gồm :
- Dữ liệu và cấu trúc dữ liệu
- Câu lệnh và dòng điều khiển
- Các tên và các tham số
- Các cơ chế tham khảo và sự tái sử dụng
Đối với những ngôn ngữ thông dụng hoặc có lịch sử dân tộc lâu dài hơn, người ta thường tổ chức triển khai những hội thảo chiến lược chuẩn hóa nhằm mục đích tạo ra và công bố những tiêu chuẩn chính thức cho ngôn ngữ đó, cũng như tranh luận về việc lan rộng ra, bổ trợ cho những tiêu chuẩn trước đó. Ví dụ : Với ngôn ngữ C + +, hội đồng tiêu chuẩn ANSI C + + và ISO C + + đã tổ chức triển khai đến 13 cuộc hội thảo chiến lược để kiểm soát và điều chỉnh và tăng cấp ngôn ngữ này. ( Xem thêm Comeau. Computing Lưu trữ 2005 – 11-07 tại Wayback Machine ). Đối với những ngôn ngữ lập trình web như JavaScript, ta có chuẩn ECMA, W3C ( [ 1 ] ) .
Các kiểu tài liệu[sửa|sửa mã nguồn]
Một hệ thống đặc thù mà theo đó các dữ liệu được tổ chức sắp xếp trong một chương trình gọi là hệ thống kiểu của ngôn ngữ lập trình. Việc thiết kế và nghiên cứu các hệ thống kiểu được biết như là lý thuyết kiểu.
Nhiều ngôn ngữ định nghĩa sẵn những kiểu tài liệu thông dụng như :
integer: rất thông dụng, được dùng để biểu diễn các số nguyên.char: biểu diễn các ký tự đơn lẻ.string: biểu diễn chuỗi các ký tự, hay còn gọi là chuỗi, để tạo thành câu hay cụm từ.
Ví dụ: trong C/C++, kiểu số nguyên thông dụng có tên là int và chiếm 4 byte trong hầu hết trình dịch 32-bit; kiểu chuỗi là một dãy các char, với ký tự NULL (hay '\0') ở vị trí chuỗi kết thúc – dãy có thể dài hơn chuỗi nó lưu trữ.
Ngôn ngữ có kiểu tĩnh là ngôn ngữ xác định trước kiểu cho tất cả dữ liệu được khai báo trong là ngôn ngữ xác lập trước kiểu cho toàn bộ tài liệu được khai báo trong mã nguồn tại thời gian dịch. Các giá trị của biến chỉ hoàn toàn có thể ở một / 1 số ít kiểu đơn cử nào đó và ta chỉ hoàn toàn có thể thực thi 1 số ít thao tác nhất định trên chúng .
Ví dụ: trong C, ta không thể dùng phép tính + trên kiểu dữ liệu string (tức là char * hay char []).
Hầu hết các ngôn ngữ có kiểu tĩnh thông dụng như C, C++, Java, D, Delphi, và C# đều đòi hỏi người lập trình kê khai rõ ràng kiểu của dữ liệu. Những người ủng hộ việc này cho rằng nó sẽ giúp ngôn ngữ rõ ràng hơn.
Các ngôn ngữ có kiểu tĩnh lại được chia ra thành hai loại :
- Ngôn ngữ kiểu khai báo, tức là sự thông báo của biến và hàm đều được khai báo riêng về kiểu của nó.
Ví dụ điển hình của loại này là Pascal, Java, C, hay C++. - Còn lại là ngôn ngữ loại suy đoán kiểu. Trong đó các biến và hàm có thể không cần được khai báo từ trước.
Linux BASH và PHP là hai ví dụ trong những kiểu này.
Suy đoán kiểu là một cơ chế mà ở đó các đặc tả về kiểu thường có thể bị loại bỏ hoàn toàn nếu có thể được, nhằm giúp cho trình dịch dễ dàng tự đoán các kiểu của các giá trị từ ngữ cảnh mà các giá trị đó được sử dụng. Ví dụ một biến được gán giá trị 1 thì trình dịch loại suy đoán kiểu không cần khai báo riêng rằng đó là một kiểuinteger. Các ngôn ngữ suy đoán kiểu linh hoạt hơn trong sử dụng, đặc biệt khi chúng lắp đặt sự đa dạng hoá các tham số. Ví dụ của ngôn ngữ loại này là Haskell, MUMPS và ML.
ngôn ngữ có kiểu động là ngôn ngữ mà các kiểu chỉ được gán lên các dữ liệu trong thời gian chương trình được thực thi. Điều này có mặt lợi là người lập trình không cần phải xác định kiểu đữ liệu nào hết, đồng thời có thêm lợi thế là có thể gán nhiều hơn một kiểu dữ liệu lên các biến. Tuy nhiên, vì ngôn ngữ có kiểu động xem tất cả các vai trò của dữ liệu trong chương trình là có thể chuyển hóa được, do vậy các phép toán không đúng (như là cộng các tên, hay là xếp thứ tự các số theo thứ tự đánh vần) sẽ không tạo ra các lỗi cho đến lúc nó được thi hành—mặc dù vẫn có một số cài đặt cung cấp vài dạng kiểm soát tĩnh cho các lỗi hiển nhiên.
Ví dụ của các ngôn ngữ này là Lisp, JavaScript, Tcl, Prolog, Cáclà ngôn ngữ mà những kiểu chỉ được gán lên những tài liệu trong thời hạn chương trình được thực thi. Điều này xuất hiện lợi là người lập trình không cần phải xác lập kiểu đữ liệu nào hết, đồng thời có thêm lợi thế là hoàn toàn có thể gán nhiều hơn một kiểu tài liệu lên những biến. Tuy nhiên, vì ngôn ngữ có kiểu động xem tổng thể những vai trò của tài liệu trong chương trình là hoàn toàn có thể chuyển hóa được, do vậy những phép toán không đúng ( như thể cộng những tên, hay là xếp thứ tự những số theo thứ tự đánh vần ) sẽ không tạo ra những lỗi cho đến lúc nó được thi hành — mặc dầu vẫn có một số ít setup cung ứng vài dạng trấn áp tĩnh cho những lỗi hiển nhiên. Ví dụ của những ngôn ngữ này là Objective-C Python và Rubyngôn ngữ có kiểu mạnh không cho phép dùng các giá trị của kiểu này như là một kiểu khác. Chúng rất chặt chẽ trong việc phát hiện sự dùng sai kiểu. Việc phát hiện này sẽ xảy ra ở thời gian thi hành (run-time) đối với các ngôn ngữ có kiểu động và xảy ra ở thời gian dịch đối với các ngôn ngữ có kiểu tĩnh.
ADA, Cáckhông được cho phép dùng những giá trị của kiểu này như thể một kiểu khác. Chúng rất ngặt nghèo trong việc phát hiện sự dùng sai kiểu. Việc phát hiện này sẽ xảy ra ở thời hạn thi hành ( ) so với những ngôn ngữ có kiểu động và xảy ra ở thời hạn dịch so với những ngôn ngữ có kiểu tĩnh. Java, ML và Oberon là những ví dụ của ngôn ngữ có kiểu mạnh .ngôn ngữ có kiểu yếu không quá khắt khe trong các quy tắc về kiểu hoặc cho phép một cơ chế tường minh để xử lý các vi phạm. Thường nó cho phép hành xử các biểu hiện chưa được định nghĩa trước, các vi phạm về sự phân đoạn (segmentation), hay là các biểu hiện không an toàn khác khi mà các kiểu bị gán giá trị một cách không đúng.
C, ASM, trái lại, không quá khắc nghiệt trong những quy tắc về kiểu hoặc được cho phép một chính sách tường minh để giải quyết và xử lý những vi phạm. Thường nó được cho phép hành xử những biểu lộ chưa được định nghĩa trước, những vi phạm về sự phân đoạn ( ), hay là những bộc lộ không bảo đảm an toàn khác khi mà những kiểu bị gán giá trị một cách không đúng. C + +, Tcl và Lua là những ví dụ của ngôn ngữ có kiểu yếu .Lưu ý :
- Các khái niệm về kiểu mạnh hay yếu có tính tương đối. Java là ngôn ngữ có kiểu mạnh đối với C nhưng yếu đối với ML. Tùy theo cách nhìn mà các khái niệm đó được dùng, nó tương tự như việc xem ngôn ngữ ASM là ở cấp thấp hơn ngôn ngữ C; trong khi Java lại là ngôn ngữ ở mức cao hơn C.
- Hai khái niệm tĩnh và mạnh cũng không đối lập nhau. Java là ngôn ngữ có kiểu mạnh và tĩnh. C là ngôn ngữ có kiểu yếu và tĩnh. Trong khi đó, Python là ngôn ngữ có kiểu mạnh và động. Tcl lại là ngôn ngữ có kiểu yếu và động. Cũng nên biết trước rằng có nhiều người đã dùng sai các khái niệm trên và cho rằng kiểu mạnh là kiểu tĩnh cộng với mạnh. Lầm lẫn hơn, họ còn cho rằng ngôn ngữ C có kiểu mạnh mặc dù rằng C không hề bắt nhiều loại lỗi về việc dùng sai kiểu.
Cấu trúc của tài liệu[sửa|sửa mã nguồn]
Hầu hết những ngôn ngữ đều phân phối những phương pháp để lắp ráp những cấu trúc tài liệu phức tạp từ những kiểu sẵn có và để link những tên với những kiểu mới phối hợp ( dùng những kiểu mảng, list, hàng đợi, ngăn xếp hay tập tin ) .
Các ngôn ngữ hướng đối tượng cho phép lập trình viên định nghĩa các kiểu dữ liệu mới gọi là đối tượng. trong nội bộ các đối tượng đó có riêng các hàm và các biến (và thường được gọi theo thứ tự là các phương thức và các thuộc tính). Một chương trình có định nghĩa các đối tượng sẽ cho phép các đối tượng đó thực thi như là các chương trình con độc lập nhưng lại tương tác nhau. Các tương tác này có thể được thiết kế trong lúc viết mã để mô hình hóa và mô phỏng theo đời sống thật của các đối tượng. Nói một cách đơn giản, các ngôn ngữ hướng đối tượng đã được cho thêm sức sống để có riêng những tính năng hoạt động và tương tác với thế giới bên ngoài. Ngoài ra, các đối tượng còn có thêm các đặc tính như là thừa kế và đa hình. Điều này là một ưu thế trong việc dùng ngôn ngữ loại này để mô tả các đối tượng của thế giới thực.
Các mệnh lệnh và dòng tinh chỉnh và điều khiển[sửa|sửa mã nguồn]
Khi tài liệu đã được định rõ, máy tính phải được thông tư làm thế nào để triển khai những phép toán trên tài liệu đó. Những mệnh đề cơ bản hoàn toàn có thể được cấu trúc trải qua việc sử dụng những từ khóa ( đã được định nghĩa bởi ngôn ngữ lập trình ) hoặc là hoàn toàn có thể tạo thành từ việc dùng và tích hợp những cấu trúc ngữ pháp hay cú pháp đã được định nghĩa. Những mệnh đề cơ bản này gọi là những câu lệnh .Tùy theo ngôn ngữ, những câu lệnh hoàn toàn có thể được tích hợp với nhau theo trật tự nào đó. Điều này được cho phép thiết lập được những chương trình thực thi được nhiều công dụng. Xa hơn, ngoài những câu lệnh để đổi khác và kiểm soát và điều chỉnh tài liệu, còn có những kiểu câu lệnh dùng để điều khiển và tinh chỉnh dòng giải quyết và xử lý của máy tính như thể phân nhánh, định nghĩa bởi nhiều trường hợp, vòng lặp, hay phối hợp những tính năng. Đây là những thành tố không hề thiếu của một ngôn ngữ lập trình .
Các tên và những tham số[sửa|sửa mã nguồn]
Muốn cho chương trình thi hành được thì phải có phương pháp xác định được các vùng trống của bộ nhớ để làm kho chứa dữ liệu. Phương pháp được biết nhiều nhất là thông qua tên của các biến. Tùy theo ngôn ngữ, các vùng trống gián tiếp có thể bao gồm các tham chiếu, mà thật ra, chúng là các con trỏ (pointer) chỉ đến những vùng chứa khác của bộ nhớ, được cài đặt trong các biến hay nhóm các biến. Phương pháp này gọi là đặt tên kho nhớ.
Tương tự với phương pháp đặt tên kho nhớ, là phương pháp đặt tên những nhóm của các chỉ thị. Trong hầu hết các ngôn ngữ lập trình, đều có cho phép gọi đến các macro hay các chương trình con như là các câu lệnh để thi hành nội dung mô tả trong các macro hay chương trình con này thông qua tên. Việc dùng tên như thế này cho phép các chương trình đạt tới một sự linh hoạt cao và có giá trị lớn trong việc tái sử dụng mã nguồn (vì người viết mã không cần phải lặp lại những đoạn mã giống nhau mà chỉ việc định nghĩa các macro hay các chương trình con.)
Các tham chiếu gián tiếp đến những chương trình khả dụng hay những bộ phận tài liệu đã được xác lập từ trước được cho phép nhiều ngôn ngữ xu thế ứng dụng tích hợp được những thao tác khác nhau .
Cơ chế tìm hiểu thêm và việc tái sử dụng mã nguồn[sửa|sửa mã nguồn]
Mỗi ngôn ngữ lập trình đều có một bộ những cú pháp pháp luật việc lập trình sao cho mã nguồn được thực thi. Theo đó, mỗi nhà phân phối ngôn ngữ lập trình sẽ phân phối một bộ những cấu trúc ngữ pháp cho những câu lệnh, một khối lượng lớn những từ vựng quy ước được định nghĩa từ trước, và một số lượng những thủ tục hay hàm cơ bản. Ngoài ra, để giúp lập trình viên thuận tiện sử dụng, nhà phân phối còn phải cung ứng những tài liệu tra cứu về đặc tính của ngôn ngữ mà họ phát hành. Những tài liệu tra cứu này bao gồm hầu hết những đặc tả, đặc thù, những tên ( hay từ khóa ) mặc định, giải pháp sử dụng, và nhiều khi là những mã nguồn để làm ví dụ. Do sự không thống nhất trong những quan điểm về việc phong cách thiết kế và sử dụng từng ngôn ngữ nên hoàn toàn có thể xảy ra trường hợp mã nguồn của cùng một ngôn ngữ chạy được cho ứng dụng dịch này nhưng không thích hợp được với ứng dụng dịch khác. Ví dụ là những mã nguồn C viết cho Microsoft C ( phiên bản 6.0 ) hoàn toàn có thể không chạy được khi dùng trình dịch Borland ( phiên bản 4.5 ) nếu không biết phương pháp kiểm soát và điều chỉnh. Đây cũng là nguyên do của những kỳ hội nghị chuẩn hóa ngôn ngữ lập trình. Ngoài việc làm chính là tăng trưởng ngôn ngữ đặc trưng, hội nghị còn tìm cách thống nhất hóa ngôn ngữ bằng cách đưa ra những tiêu chuẩn, những khuyến nghị biến hóa về ngôn ngữ trong tương lai hay những thay đổi về cú pháp của ngôn ngữ .Những thay đổi về tiêu chuẩn của một ngôn ngữ mặt khác lại hoàn toàn có thể gây ra những hiệu ứng phụ. Đó là việc mã nguồn của một ngôn ngữ dùng trong phiên bản cũ không thích hợp được với ứng dụng dịch dùng tiêu chuẩn mới hơn. Đây cũng là một việc cần lưu tâm cho những người lập trình. Trường hợp nổi bật nhất là việc biến hóa phiên bản về ngôn ngữ Visual Basic của Microsoft. Các mã nguồn của phiên bản 6.0 hoàn toàn có thể sẽ không dịch được nếu dùng phiên bản mới hơn. Lý do là nhà phong cách thiết kế đã đổi khác kiến trúc của VisualBasic để nâng cao và cung ứng thêm những công dụng mới về lập trình theo khuynh hướng đối tượng người dùng cho ngôn ngữ này .Thay vào việc tái sử dụng mã nguồn thì cũng có những hướng tăng trưởng khác nhằm mục đích tiết kiệm ngân sách và chi phí sức lực lao động cho người lập trình mà hai hướng chính là :
- Việc ra đời của các bytecode mà điển hình là ngôn ngữ Java. Với Java thì mã nguồn sẽ được dịch thành một ngôn ngữ trung gian khác gọi là bytecode. Mã của bytecode một lần nữa sẽ được phần mềm thông dịch thực thi, phần mềm này gọi là máy ảo. Các máy ảo được cài đặt sẵn trên các máy tính và được cung cấp miễn phí. Tùy theo hệ điều hành mà có thể cài đặt máy ảo thích hợp. Do đó, cùng một nguồn Java bytecode có thể chạy trong bất cứ hệ điều hành nào miễn là hệ điều hành đó có cài đặt sẵn máy ảo Java. Việc này tiết kiệm rất nhiều công sức cho lập trình viên vì họ không phải viết mã Java khác nhau cho mỗi hệ điều hành.
- Tận dụng tính chất thừa kế của các lớp (class) trong các ngôn ngữ hướng đối tượng. Theo kiểu thiết kế này, một đối tượng có thể thụ hưởng các đặc tính mà các thế hệ trước của chúng đã có. Do đó, khi phát triển phần mềm mới theo cấu trúc của các lớp, người ta chỉ cần tạo thêm các lớp con (subclass) có nhiều tính năng mới hơn. Điều này giúp giảm bớt công sức vì không phải phát triển lại từ đầu. (Lưu ý: Java cũng là một loại ngôn ngữ hướng đối tượng nên nó có luôn ưu thế này.)
Triết lý của những phong cách thiết kế[sửa|sửa mã nguồn]
Tùy theo mục tiêu của ngôn ngữ mà chúng được phong cách thiết kế để tạo điều kiện kèm theo xử lý những yếu tố mà ngôn ngữ đó hướng tới. Những tính năng này làm cho một ngôn ngữ hoàn toàn có thể tiện nghi để dùng tăng trưởng loại ứng dụng này nhưng hoàn toàn có thể khó để tăng trưởng loại ứng dụng khác .
Hầu hết các ngôn ngữ đòi hỏi sự chính xác cao về mặt cú pháp. Các ngôn ngữ không cho phép có lỗi. Mặc dù vậy, một số ít ngôn ngữ cũng cho phép tự điều chỉnh trong một mức độ khá cao, khi đó chương trình tự viết lại để xử lý những trường hợp mới. Các ngôn ngữ như Prolog, PostScript và các thành viên trong họ ngôn ngữ Lisp có khả năng này. Trong ngôn ngữ MUMPS, kỹ thuật này gọi là tái biên dịch động. Các phần mềm mô phỏng và nhiều máy ảo (virtual machine) khai thác kỹ thuật này để có hiệu suất cao.
Một yếu tố tương quan đến triết lý phong cách thiết kế là có một số ít ngôn ngữ vì muốn tạo sự thuận tiện cho người mới dùng, đã không phân biệt việc viết chữ hoa hay không. Pascal và Basic là hai ngôn ngữ không phân biệt việc một ký tự có viết hoa hay không, trái lại trong C / C + +, Java, PHP, Perl, BASH đều bắt buộc phải bảo vệ việc viết đúng y hệt như lúc khai báo cho những tên .
Các thành tố cơ bản của một ngôn ngữ[sửa|sửa mã nguồn]
Các dạng câu lệnh[sửa|sửa mã nguồn]
Câu lệnh là một thành tố quan trọng nhất của mọi ngôn ngữ lập trình. Tùy theo ngôn ngữ những câu lệnh đều phải tuân theo những trật tự sắp xếp của những từ khóa, tham số, biến và những định danh khác như những macro, hàm, thủ tục cũng như những quy ước khác. Tập hợp trật tự và quy tắc đó tạo thành cú pháp của ngôn ngữ lập trình. Các dạng câu lệnh bao gồm
- Định nghĩa: Dạng câu lệnh này cho phép xác định một kiểu dữ liệu mới hay một : Dạng câu lệnh này được cho phép xác lập một kiểu tài liệu mới hay một hằng. Lưu ý là trong những ngôn ngữ lập trình xu thế đối tượng người dùng thì mỗi lớp đều hoàn toàn có thể là một kiểu tài liệu mới do đó việc tạo ra một lớp mới tức là đã dùng câu lệnh kiểu định nghĩa .
- Ví dụ: Trong C hay C++, câu lệnh
#define PI 3.1415927sẽ cho phép định nghĩa tên (macro) PI với giá trị không đổi là 3,1415927.
-
Khai báo: Cũng gần giống như dạng định nghĩa, dạng khai báo cho phép người lập trình chính thức thông báo về sự ra đời của một biến, hay một tên (tên hàm chẳng hạn). Thông thường, đối với ngôn ngữ tĩnh, tên hàm hay biến mới đều phải có phần cho biết kiểu dữ liệu của biến hay hàm. Tuy nhiên, điều này không bắt buộc với ngôn ngữ động. Ngoài ra, các khai báo đôi khi còn cho phép các biến gán một giá trị ban đầu nhưng thường thì việc này cũng không bắt buộc. (Xem thêm loại câu lệnh gán giá trị). Đối với nhiều ngôn ngữ thì việc khai báo có thể cho phép chương trình đó được cấp thêm một phần bộ nhớ dự trữ riêng cho các biến (hay các đối tượng) đăng ký tên trong câu lệnh khai báo.
- Ví dụ:
- Trong Java hay C/C++, câu lệnh
int line_number = 0;thuộc loại khai báo - Trong Perl hay PHP, câu lệnh
$my_var;thuộc loại khai báo
- Trong Java hay C/C++, câu lệnh
-
Gán giá trị là loại câu lệnh cho phép viết giá trị cụ thể vào các biến. Có thể có các giới hạn khác nhau trong việc gán giá trị này (chẳng hạn như phải tương thích về kiểu dữ liệu hay trường hợp nếu biến có các kiểu đặc biệt thì phải dùng đến các hàm hay các thủ tục để gán giá trị cho chúng).
- Ví dụ:
- Trong ASM, câu lệnh
mov AX, 21hsẽ gán giá trị 21h lên thanh AX - Trong Java hay C/C++, câu lệnh
i = j;sẽ gán giá trị đang có của biến j cho biến i
- Trong ASM, câu lệnh
-
Kết hợp: Hầu hết các ngôn ngữ đều cho phép thiết lập câu lệnh mới từ nhiều câu lệnh. Lưu ý: Cần dựa theo cú pháp của từng ngôn ngữ để làm việc này.
- Ví dụ:Trong văn lệnh BASH hai câu lệnh xóa các tệp có đuôi txt
rm -f *.txtvà câu lệnhmkdir newfoldertạo một thư mục trống có tên ‘newfolder’ có thể được ghép nhau thành dãy câu có dạngrm -f *.txt; mkdir newfolder. Thứ tự thực hiện các câu lệnh thành phần sẽ đi từ trái sang phải.
-
Điều kiện: Loại câu lệnh này dùng để chẻ nhánh dòng điều khiển của ngôn ngữ. Thường từ khóa hay được dùng nhất là
"if", "else", và "else if". Ngoài ra, một số ngôn ngữ có thể dùng thêm dạng câu lệnh phân nhánh đặc biệt cho trường hợp có nhiều phân nhánh (thường từ khóa bắt đầu câu lệnh điều kiện kiểu này có thể là"switch" hay là "case".)
- Ví dụ: Trong Java hay C/C++, câu lệnh
if (x==1) { y = x; }else { y = x + 3; }- là loại câu lệnh điều kiện
-
Vòng lặp: Dùng để lặp lại các câu lệnh giống nhau cho các đối tưọng hay các biến trong một số hữu hạn lần. Từ khóa thường gặp nhất trong các ngôn ngữ là
"for" và "while".
- Ví dụ: Trong Java hay C/C++, câu lệnh
for (int n=1; n!=5; ++n) { value *= n }- sẽ lần lượt tính giá trị
value = value * nlàm 4 lần với các giá trị của biến n lần lượt là 1,2,3,4. Giá trị sau cùng nhận về của value sẽ là (value * 4!).
- Gọi loại lệnh này dùng để thực thi các hàm, các thủ tục, hay các loại lệnh này dùng để thực thi những hàm, những thủ tục, hay những macro đã được định nghĩa sẵn bởi những thư viện hay bởi người lập trình .
- Ví dụ: Trong C/C++, câu lệnh
printf("Hello, world!\n");- gọi hàm cho sẵn nhằm hiển thị dòng chữ
- “
Hello, world!“
-
Các định hướng dịch hay còn gọi là các chỉ thị tiền xử lý: Ngoài các thành tố trên, các nhà sản xuất các phần mềm dịch (đặc biệt là các trình dịch) còn có thể cung cấp thêm các dạng câu lệnh không trực tiếp tham gia vào việc tính toán trên các dữ liệu của chương trình nhưng lại trực tiếp điều khiển các dòng chuyển dịch mã ở thời điểm dịch cũng như là hướng dẫn các trình dịch cách xử lý, tìm nguồn mã bổ sung, cách dùng thư viện, hay các cài đặt đặc biệt cho một loại hệ điều hành hay cho một loại phần cứng nào đó. Các câu lệnh này có thể tùy thuộc vào nhà sản xuất phần mềm chuyển dịch cung cấp.
- Ví dụ: Trong C/C++ các câu lệnh
#ifndef MY_LIB#include "my_code.h"#endif- sẽ kiểm tra nếu tên MY_LIB chưa được định nghĩa trước đây trong chương trình thì sẽ tiếp tục đọc tệp my_code.h (để nhận vào các định nghĩa, hay các khai báo có trong tệp my_code.h rồi tiếp tục dịch mã.)
- Thí du: Trong Java, C/C++, PHP các câu chú giải có thể bắt đầu bởi dấu “//”
//hàm "SUM(n,r,m)" dùng để tính tổng số tiền có được khi gửi ngân hàng// n=số tháng, r = lãi suất trong năm, m = vốn gửi ban đầu- sẽ là hai câu lệnh chú giải.
Lưu ý : để hiểu rõ hơn và sử dụng thuần thục những dạng câu lệnh thì người lập trình nên tìm hiểu thêm những tài liệu giảng giải riêng về từng ngôn ngữ .
Chương trình con và macro[sửa|sửa mã nguồn]
- Một chương trình con (còn được gọi là hàm, thủ tục, hay thủ tục con) là một chuỗi mã để thực thi một thao tác đặc thù nào đó như là một phần của chương trình lớn hơn. Đây là các câu lệnh được nhóm vào một khối và được đặt tên và tên này tùy theo ngôn ngữ có thể được gán cho một kiểu dữ liệu. Những khối mã này có thể được tập trung lại làm thành các thư viện phần mềm. Các chương trình con có thể được gọi ra để thi hành (thường là qua tên của chương trình con đó). Điều này cho phép các chương trình dùng tới những chương trình con nhiều lần mà không cần phải lặp lại các khối mã giống nhau một khi đã hoàn tất việc viết mã cho các chương trình con đó chỉ một lần.
Trong một số ít ngôn ngữ, người ta lại phân biệt thành 2 kiểu chương trình con :
- Hàm (function) dùng để chỉ các ) dùng để chỉ những chương trình con nào có giá trị trả về ( trong một kiểu tài liệu nào đó ) trải qua tên của hàm .
- Thủ tục (subroutine) dùng để mô tả các ) dùng để miêu tả những chương trình con được thi hành và không có giá trị trả về .
Tuy nhiên, trong nhiều ngôn ngữ khác như C chẳng hạn thì không có sự phân biệt này và chỉ có một khái niệm hàm. Để mô tả các hàm không trả về giá trị (tương đương với khái niệm thủ tục) thì người ta có thể gán cho kiểu dữ liệu của hàm đó là void.
Lưu ý: trong các ngôn ngữ hướng đối tượng, mỗi một đối tượng hay một thực thể (instance), tùy theo quan điểm, có thể được xem là một chương trình con hay một biến vì bản thân nội tại của thực thể đó có chứa các phương thức và cả các dữ liệu có thể trả lời cho các lệnh gọi từ bên ngoài.
- macro được hiểu là tên viết tắt của một tập các câu lệnh. Như vậy, trong những chương trình có các khối câu lệnh giống nhau thì người ta có thể định nghĩa một macro cho khối đại diện và có thể dùng tên của macro này trong lúc viết mã thay vì phải viết cả khối câu lệnh mỗi lần khối này xuất hiện lặp lại. Một cách trừu tượng, thì macro là sự thay thế một dạng thức văn bản xác định bằng việc định nghĩa của một (hay một bộ) quy tắc. Trong quá trình dịch, các phần mềm dịch sẽ tự động thay các macro này trở lại bằng các mã mà nó viết tắt cho, rồi mới tiếp tục dịch. Như vậy, các mã này được điền trả lại trong thời gian dịch. Một số ngôn ngữ có thể cho các macro được phép khai báo và sử dụng tham số. Như vậy về vai trò macro giống hệt như các chương trình con.
Các điểm khác nhau quan trọng giữa một chương trình con và một macro bao gồm :
- Mã của chương trình con vẫn được dịch và để riêng ra. Cho tới khi một chương trình con được gọi ở thời điểm thi hành, thì các mã đã dịch sẵn của chương trình con này mới được lắp vào dòng chạy của chương trình.
Trong khi đó, sau khi dịch, các macro sẽ không còn tồn tại. Trong chương trình đã được dịch, tại các vị trí có tên của macro thì các tên này được thay thế bằng khối mã (đã dịch) mà nó đại diện. - Cách viết mã dùng chương trình con sau khi dịch xong sẽ tạo thành các tập tin ngắn hơn so với cách viết dùng macro.
- Ngược lại khi máy tính tải lên thì một phần mềm có cách dùng macro ít tốn tính toán của CPU hơn là phần mềm đó phát triển bằng phương pháp gọi các chương trình con.
Biến, hằng, tham số, và đối số[sửa|sửa mã nguồn]
- Một biến (variable) là một tên biểu thị cho một số lượng, một ký hiệu hay một đối tượng. Thêm vào đó, một biến sẽ được dành sẵn chỗ (phần của bộ nhớ) để chứa số lượng, ký hiệu hay đối tượng đó. Trong lúc chương trình được thi hành thì các biến của chương trình sẽ có thể thay đổi giá trị hoặc không thay đổi gì cả. Hơn nữa, một biến có thể bị thay đổi cả lượng bộ nhớ mà nó đang chiếm hữu (do người lập trình hay do phần mềm dịch ra lệnh). Trường hợp biến này không được gán giá trị hay có gán giá trị nhưng không được sử dụng vào các tính toán thì nó chỉ chiếm chỗ trong bộ nhớ một cách vô ích. Mỗi biến sẽ có tên của nó và có thể có kiểu xác định. Tùy theo ngôn ngữ, một biến có thể được khai báo ở vị trí nào đó trong mã nguồn và cũng tùy ngôn ngữ, tùy phần mềm dịch và cách thức lập trình mà một biến có thể được tạo nên (cùng với chỗ chứa) hay bị xóa bỏ tại một thời điểm nào đó trong lúc thực thi chương trình. Việc các biến bị xóa bỏ là để tiết kiệm bộ nhớ cũng như làm tốt hơn việc quản lý phần bộ nhớ mà đôi khi một chương trình chỉ được cấp bởi đăng ký với hệ điều hành.
Quá trình tồn tại của một biến gọi là đời sống của biến. Trong nhiều trường hợp đời sống của một biến chỉ xảy ra trong nội bộ một hàm, một thủ tục hay trong một khối mã.
- Một hằng (constant) là một giá trị số hay ký hiệu được gán cho một tên xác định. Khác với biến, hằng không bao giờ thay đổi giá trị. Vì lý do tiện lợi trong việc viết mã, thường đời sống của một hằng lâu dài hơn một biến và có khi nó tồn tại trong suốt toàn bộ thời gian thi hành của chương trình. Trong nhiều trường hợp hằng có thể được xác định kiểu hay không. (C++ là ngôn ngữ cho phép có cả hai cách định nghĩa hằng có kiểu hay không có kiểu và câu lệnh để tạo ra hai loại này là hoàn toàn khác nhau). Nếu một biến hoàn toàn không thay đổi giá trị của nó trong mọi tình huống thì vai trò của biến này tương đương với một hằng.
- Khác với biến, tham số (parameter) cũng là các tên được các chương trình con hay macro dùng để tính toán. Khi được gọi thì chương trình con, hay macro sẽ đòi hỏi các tên này phải được gán giá trị cụ thể trước khi tiến hành tính toán.
- Các giá trị được gán lên cho các tham số để một chương trình con hay macro thi hành gọi là các đối số (argument). Một cách đơn giản, các đối số là các giá trị thông tin hay dữ liệu cung cấp cho các chương trình con hay macro trước khi tính toán.
Các tham số giống biến ở chỗ chúng thường có kiểu xác lập. Bên trong chương trình con, hay macro, những tham số thường đóng vai trò của hằng nhưng trong nhiều trường hợp khác chúng vẫn hoàn toàn có thể hoạt động giải trí như những biến và điều này cũng phụ thuộc vào vào những đặc tính của mỗi ngôn ngữ .Nếu nhìn hàng loạt chương trình như một hàm lớn thì tham số của hàm này gọi là tham số của chương trình và những tham số của chương trình này hoàn toàn có thể tương tác với những chương trình khác và ngược lại. Một cách đơn thuần thì tham số là những tài liệu truyền đi giữa những chương trình hay những hàm, thủ tục hay macro .
Từ vựng quy ước[sửa|sửa mã nguồn]
Từ vựng quy ước là những dãy các ký tự hay ký hiệu (thường tạo thành các chữ có ý nghĩa) nối nhau và được một ngôn ngữ cho sử dụng như là tên, giá trị hay một luật nào đó. Người viết mã nên tránh sử dụng các từ quy ước này vào việc đặt tên (cho các biến, hàm, hay các đối tượng khác) để tránh không gây ra các lỗi dạng ambiguity (nghĩa là từ dùng có nhiều nghĩa khiến cho phần mềm dịch không biết phải chọn cách nào). Tuy nhiên, tuỳ theo từng trường hợp mà một tên mới đặt ra trùng với các tên đã quy định có được chấp nhận hay không và việc chấp nhận này sẽ có hiệu ứng phụ gì.
Thí dụ
- Trong C thì việc viết
#define MYVALUE 10;thì dãy ký tự “#define” sẽ là một từ vựng quy ước (thuộc về câu lệnh dạng định nghĩa) - Trong C/C++ nếu dùng từ
intđể khai báo như là tên của một biến chẳng hạn nhưunsigned int;thì lập tức khai báo này sẽ bị trình dịch bắt lỗi.
 Công cụ tô màu cú pháp (syntax highlighting) dùng màu sắc để giúp lập trình viên thấy nhiệm vụ của các từ khóa, số, và dòng chú thích (comment) trong mã nguồn. Chương trình này được viết trong ngôn ngữ Python, nó tính ra thể tích của hình nón.
Công cụ tô màu cú pháp (syntax highlighting) dùng màu sắc để giúp lập trình viên thấy nhiệm vụ của các từ khóa, số, và dòng chú thích (comment) trong mã nguồn. Chương trình này được viết trong ngôn ngữ Python, nó tính ra thể tích của hình nón.
Từ khóa trong ngôn ngữ lập trình là các từ hay ký hiệu mà đã được ngôn ngữ đó gán cho một ý nghĩa xác định. Người lập trình sẽ không được phép dùng lại các từ khóa này dưới một ý nghĩa khác. Thường các từ khóa này được ngôn ngữ xác định dùng trong các kiểu dữ liệu cơ bản hay trong các dòng điều khiển. Ví dụ một số từ khóa trong C và C++: auto, float, return, char, if else, static, void...
Các tên chuẩn hay tên cho trước[sửa|sửa mã nguồn]
Ngoài những từ khóa, một ngôn ngữ lập trình còn có khối lượng khá lớn những tên đã được định nghĩa hay được gán cho những ý nghĩa chuyên biệt gọi là những tên chuẩn. Các tên này hoàn toàn có thể được dùng lại cho một ý nghĩa khác tùy theo người viết mã. Trong nhiều trường hợp sẽ phải có một chính sách gọi để phân biệt là người lập trình muốn ám chỉ những tên đã bị tái dụng này dưới ý nghĩa nguyên thủy hay dưới ý nghĩa mới. Thường những tên được phép định nghĩa lại nằm trong hai loại chính là :
- Các hàm hay thủ tục chuẩn.
- Các biến toàn cục (global)
Ví dụ
- Trong C thì
sinlà tên của một hàm tính giá trị sin (trong thư viện math.h) nhưng người lập trình hoàn toàn có thể định nghĩa lại hàm này để cho nó có chức năng khác. - Trong văn lệnh BASH thì biến toàn cục
$PATHcó thể được định nghĩa lại để dùng như là một biến địa phương.
Các ký hiệu[sửa|sửa mã nguồn]
Trong mỗi ngôn ngữ đều phân phối một mạng lưới hệ thống ký hiệu hay ký tự có ý nghĩa riêng. Tùy theo ngôn ngữ mà những ký hiệu này được phép định nghĩa lại hay không. Những ký hiệu được dùng trong hai trường hợp thường thấy nhất là
- Dùng để chỉ các phép toán.
- Dùng trong cú pháp. Trường hợp này thì các ký hiệu này giữ vai trò tương tự như các dấu chấm câu trong các ngôn ngữ tự nhiên.
Ví dụ :
- Trong C/C++/Java/PHP thì các dấu ký hiệu
'+', '-', '*', '/', '='được dùng trong các phép toán theo thứ tự là cộng, trừ, nhân, chia và phép toán gán giá trị. - Trong C thì các dấu
'+', '-', '*', '/',...là không thể dùng lại cho ý nghĩa khác. Trong khi đó nếu dùng C++ thì người lập trình hoàn toàn có khả năng định nghĩa chúng lại thành những phép toán mới theo ý riêng và áp dụng cho các đối tượng mà người lập trình mong muốn (chẳng hạn như dùng phương pháp “quá tải toán tử”). - Trong C, C++, PHP, Perl, Java và Pascal thì kết thúc các câu lệnh đơn giản thường bắt buộc phải dùng dấu
';'. Và điều này thì không nhất thiết nếu dùng văn lệnh BASH. Dấu ‘;’ này giữ vai trò tương tự như dấu ‘.’ trong Việt ngữ hay Anh ngữ. (Có điều là đại đa số các ngôn ngữ lập trình sẽ tuyệt đối không cho phép việc viết sai cú pháp.)
Các luật cấm và ngoại lệ[sửa|sửa mã nguồn]
Mỗi ngôn ngữ, do hạn chế của thiên nhiên và môi trường và bản thân ngôn ngữ cũng như do tiềm năng sử dụng, hoàn toàn có thể có 1 số ít luật cấm mà người lập trình không hề vi phạm. Những luật cấm này hoàn toàn có thể có những cách giải quyết và xử lý khác nhau như thể :
- Nhiều ngôn ngữ cho phép dùng các câu lệnh đặc biệt để lập trình viên có toàn quyền xử lý lỗi và thường được gọi là ngoại lệ (hay exception). Những ngoại lệ này nếu không xử lý đúng mức sẽ có thể gây ra những sai sót trong thời gian thi hành hay ngay cả trong thời gian dịch. Dĩ nhiên, người viết mã có thể tùy theo tình huống mà viết các câu lệnh rẽ nhánh tránh không để cho mã vi phạm các lỗi. Hay là dùng các câu lệnh xử lý các ngoại lệ này.
- Một số ngôn ngữ không cung cấp khả năng xử lý ngoại lệ thì người viết mã buộc phải tự mình phán đoán hết các tình huống có thể vi phạm lỗi và dùng câu lệnh điều kiện để loại trừ.
Các loại lỗi về ngôn ngữ khi lập trình thường xảy ra là
Lỗi cú pháp[sửa|sửa mã nguồn]
- Vi phạm khi đặt hay gọi tên biến và hàm: Lỗi loại này thường rất dễ tìm ra trong lúc phát triển mã. Thường người ta có thể đọc lại các bảng tham chiếu về ngôn ngữ để tránh sai cú pháp mẫu (prototype) của hàm hay tránh dùng các ký tự đặc biệt bị cấm không cho dùng trong khi đặt tên. Trong không ít trường hợp người lập trình có thể đã định nghĩa cùng một tên cho nhiều hơn một đối tượng khác nhau và lại có giá trị toàn cục. Trong nhiều trường hợp chúng tạo thành lỗi ý nghĩa.
- Lỗi chính tả: người viết mã có thể viết hay gọi sai tên hàm, tên biến. Trong nhiều ngôn ngữ có kiểu tĩnh thì các lỗi này sẽ rất dễ bị phát hiện. Còn đối với ngôn ngữ có kiểu động hay có kiểu yếu thì nó có thể dẫn đến sai sót nghiêm trọng vì bản thân phần mềm dịch không hề phát hiện ra.
- Vượt quá khả năng tính toán: Bản thân máy tính và hệ điều hành cũng có rất nhiều giới hạn về phần cứng, phần mềm và các đặc điểm chuyên biệt. Khi người lập trình yêu cầu máy làm quá khả năng sẽ gây ra các lỗi mà đôi khi không xác định được như
- Lỗi thời gian (timing error) thường thấy trong các hệ thống đa luồng hay đa nhiệm.
- Lỗi chia cho 0: Bản thân phần cứng máy tính sẽ ở trạng thái bất định khi thực hiện phép chia cho 0; trong nhiều trường hợp, mã sau khi dịch mới phát hiện ra trong lúc thi hành và được đặt tên là lỗi division by 0.
- Dùng hay gọi tới các địa chỉ hay các thiết bị mà bản thân máy hay hệ điều hành đang thực thi lại không có hay không thể đạt tới. Đây là trường hợp rất khó lường. Bởi vì thường người lập trình có thể viết mã trên một máy nhưng lại cho thi hành trong các máy khác và các máy này lại không thỏa mãn các yêu cầu. Để giảm trừ các lỗi loại này thường người lập trình nên xác định trước các điều kiện mà phần mềm làm ra sẽ hỗ trợ.
-
- Ví dụ: trong nhiều phần mềm ngày nay ở trong vỏ hộp đều được ghi rõ các yêu cầu về vận tốc, bộ nhớ tối thiểu, và quan trọng là hệ điều hành nào mà phần mềm đó hỗ trợ.
- Gán sai dữ liệu: Tức là dùng một dữ liệu có kiểu khác với kiểu của biến để gán cho biến đó một cách không chủ ý. Đối với các ngôn ngữ tĩnh hay có kiểu mạnh thì lỗi này dễ tìm thấy hơn. Còn những ngôn ngữ động hay ngôn ngữ có kiểu yếu thì lỗi tạo ra sẽ có thể khó phát hiện và thường xảy ra lúc thi hành.
- Các lỗi biên: Lỗi biên thường xảy ra khi người viết mã không chú ý đến các giá trị ở biên của các biến, các hàm. Những lỗi để thấy có thể là:
- Gán giá trị của một số (hay một chuỗi) lên một biến mà nó vượt ngoài sự cho phép của định nghĩa.
Ví dụ: Gán một giá trị lớn hơn 255 cho một biến có kiểu làshorttrong ngôn ngữ C - Tạo nên các lỗi khi biến chạy trong vòng lặp đạt giá trị ở biên.
Ví dụ: đoạn mã C/C++ sau đây sẽ gây ra lỗi biên—Chia cho 0
- Gán giá trị của một số (hay một chuỗi) lên một biến mà nó vượt ngoài sự cho phép của định nghĩa.
-
for (m=10; m >= 0, m--) {x= 8+ 2/m; }
Lỗi ý nghĩa[sửa|sửa mã nguồn]
- Lỗi về quản lý bộ nhớ. Trong nhiều loại ngôn ngữ người lập trình có thể xin đăng ký một lượng nào đó của bộ nhớ để dùng làm chỗ chứa giá trị cho một biến (một hàm hay một đối tượng). Thường thì sau khi dùng xong người viết mã phải có phần lệnh trả về các phần bộ nhớ mà nó đã đăng ký dùng. Nếu không, sự trả về này chỉ xảy ra ở giai đoạn kết thúc việc thi hành. Trong nhiều trường hợp, số lượng bộ nhớ xin đăng ký quá nhiều và không được dùng đúng chỗ có thể làm cho máy kiệt quệ về mặt tài nguyên bộ nhớ và gây ra treo máy. Điển hình nhất là việc xin đăng ký các phần của bộ nhớ trong các vòng lặp lớn để gán cho các đối tượng bên trong vòng lặp nhưng không trả về sau khi sử dụng. Người ta thường gọi lỗi kiểu này là lỗi rò rỉ bộ nhớ (memory leaking).
- Sai sót trong thuật toán: Trước khi viết một chương trình, để giảm thiểu sai sót về mặt lập luận thì người ta có nhiều biện pháp để làm giảm lỗi trong đó có các phương pháp vẽ lưu đồ, vẽ sơ đồ khối, hay viết mã giả. Những biện pháp này nhằm tạo nên các thuật toán để giải quyết vấn đề. Tuy nhiên, một thuật toán không chặt chẽ, xử lý không rốt ráo mọi trường hợp có thể xảy ra, không dự đoán được sự thay đổi trong lúc thi hành thì có thể tạo nên các lỗi và các lỗi này thường khó thấy bởi vì nó chỉ xảy ra ở những chỗ, những thời điểm mà người lập trình không ngờ trước. Một trong những phương pháp đơn giản làm giảm thiểu lỗi thuật toán là phải chú ý xử lý mọi tình huống khi dùng câu lệnh điều kiện (hay chẻ nhánh) mặc dù có thể có các trường hợp tưởng như hiển nhiên.
- Lỗi về lập luận: Đây có thể xem là trường hợp đặc biệt của sai sót trong thuật toán. Trong các biểu thức tính giá trị, đôi khi không quen dùng đại số Bool (nhất là khi dùng luật De Morgan để phủ định một biểu thức phức tạp) nên người lập trình có thể tính toán sai, hay định nghĩa sai các phép toán. Do đó, giá trị trả về của các biểu thức logic hay biểu thức nhị phân sẽ bị sai trong một vài trường hợp hay toàn bộ biểu thức. Trong những tình huống như vậy phần mềm dịch sẽ không thể nào phát hiện ra cho đến khi chương trình được thi hành và lọt vào tình huống tính sai của người lập trình.
Các thành tố đặc trưng của ngôn ngữ OOP[sửa|sửa mã nguồn]
OOP là chữ viết tắt của Object Oriented Programming có nghĩa là Lập trình hướng đối tượng được phát minh năm 1965 bởi Ole-Johan Dahl và Kristen Nygaard trong ngôn ngữ Simula. So với phương pháp lập trình cổ điển, thì triết lý chính bên trong loại ngôn ngữ loại này là để tái dụng các khối mã nguồn và cung ứng cho các khối này một khả năng mới: chúng có thể có các hàm (gọi là các phương thức) và các dữ liệu (gọi là thuộc tính) nội tại. Khối mã như vậy được gọi là đối tượng. Các đối tượng thì độc lập với môi trường và có khả năng trả lời với yêu cầu bên ngoài tùy theo thiết kế của người lập trình. Với cách xây dựng này, mỗi đối tượng sẽ tương đương với một chương trình riêng có nhiều đặc tính mới mà quan trọng nhất là tính đa hình, tính đóng, tính trừu tượng và tính thừa kế.
Đây là đặc tính được cho phép tạo những đối tượng người dùng mới từ đối tượng người dùng bắt đầu và lại hoàn toàn có thể có thêm những đặc tính riêng mà đối tượng người tiêu dùng khởi đầu không có. Cơ chế này được cho phép người lập trình hoàn toàn có thể tái sử dụng mã nguồn cũ và tăng trưởng mã nguồn mới bằng cách tạo ra những đối tượng người dùng mới thừa kế đối tượng người dùng bắt đầu .
Tính đa hình được bộc lộ trong lập trình hướng đối tượng người tiêu dùng rất đặc biệt quan trọng. Người lập trình hoàn toàn có thể định nghĩa một thuộc tính ( ví dụ điển hình trải qua tên của những phương pháp ) cho một loạt những đối tượng người tiêu dùng gần nhau nhưng khi thi hành thì dùng cùng một tên gọi mà sự thi hành của mỗi đối tượng người dùng sẽ tự động hóa xảy ra tương ứng theo từng đối tượng người tiêu dùng không bị nhầm lẫn .
- Ví dụ: khi định nghĩa hai đối tượng “hinh_vuong” và “hinh_tron” thì có một phương thức chung là “chu_vi”. Khi gọi phương thức này thì nếu đối tượng là “hinh_vuong” nó sẽ tính theo công thức khác với khi đối tượng là “hinh_tron”.
Đặc tính này được cho phép xác lập một đối tượng người dùng trừu tượng, nghĩa là đối tượng người tiêu dùng đó hoàn toàn có thể có 1 số ít đặc thù chung cho nhiều đối tượng người tiêu dùng nhưng bản thân đối tượng người tiêu dùng này hoàn toàn có thể không có những giải pháp thi hành .
- Ví dụ: người lập trình có thể định nghĩa đối tượng “hinh” hoàn toàn trừu tượng không có đặc tính mà chỉ có các phương thức được đặt tên chẳng hạn như “chu_vi”, “dien_tich”. Để thực thi thì người lập trình buộc phải định nghĩa thêm các đối tượng cụ thể chẳng hạn định nghĩa “hinh_tron” và “hinh_vuông” dựa trên đối tượng “hinh” và hai định nghĩa mới này sẽ thừa kế mọi thuộc tính và phương thức của đối tượng “hinh”.
Tính đóng gói ở đây dược hiểu là những tài liệu ( thuộc tính ) và những hàm ( phương pháp ) bên trong của mỗi đối tượng người tiêu dùng sẽ không được cho phép người gọi dùng hay biến hóa một cách tự do mà chỉ hoàn toàn có thể tương tác với đối tượng người tiêu dùng đó qua những phương pháp được người lập trình cho phép. Tính đóng gói ở đây hoàn toàn có thể so sánh với khái niệm ” hộp đen “, nghĩa là người ta hoàn toàn có thể thấy những hành vi của đối tượng người tiêu dùng tùy theo nhu yếu của môi trường tự nhiên nhưng lại không hề biết được cỗ máy bên trong thi hành thế nào .
Một số thành tố thường thấy khác của một ngôn ngữ lập trình tân tiến[sửa|sửa mã nguồn]
Nhiều ngôn ngữ lập trình tân tiến, nhất là những ngôn ngữ viết cho Windows, thường có cung ứng thêm một số lượng rất lớn những thư viện bao gồm nhiều hàm để tương hỗ giao diện người dùng và những thiết bị đầu cuối .
Giao diện đồ họa[sửa|sửa mã nguồn]
Các ngôn ngữ chuẩn thường không đề cập tới sự cung cấp thư viện giúp cho việc thiết lập giao diện đồ họa (graphic interface). Nhưng hầu hết trong các ngôn ngữ hiện đại mà nhà sản xuất cung cấp cho các hệ điều hành đều có thêm thư viện các hàm và các biến toàn cục có thể dùng để nhanh chóng viết mã có giao diện phù hợp.
- Ví dụ như GDK (cho Linux), Java (cho mọi hệ), Visual C/C++/C# (cho Windows),… Và các thư viện này ngày nay đã trở thành các thành tố không thể thiếu cho người lập trình.
Điều khiển theo sự kiện[sửa|sửa mã nguồn]
Tương tự trên, triết lý đằng sau của việc điều khiển và tinh chỉnh theo sự kiện là để tương hỗ cho việc đồng điệu sử dụng cùng lúc nhiều thiết bị đầu cuối như là chuột, bàn phím, máy in, … Việc nhận một mệnh lệnh từ chuột hay từ bàn phím phải được lập tức đồng nhất và biến hóa giao diện tức thời để update hóa .
Thời gian thực[sửa|sửa mã nguồn]
Bản thân một ngôn ngữ sẽ không nói rõ là có tương hỗ cho tính năng này hay không. Phản ứng và update tài liệu theo thời hạn thực là một hướng tăng trưởng nhằm mục đích cung ứng những nhu yếu đồng điệu hóa nhanh tài liệu mà chúng hoàn toàn có thể san sẻ cho nhiều nơi hay là để thỏa mãn nhu cầu nhu yếu thiết yếu đồng nhất hóa dữ liệu của những dịch vụ ( ngân hàng nhà nước, hàng không và quân sự chiến lược ví dụ điển hình ) .
Hỗ trợ hệ quản lý và điều hành[sửa|sửa mã nguồn]
Ngoài các hỗ trợ cho các giao diện thì ngày nay hầu hết các hệ điều hành (Linux/UNIX, Netware và Windows) đều có khả năng đa luồng (multithreading) hay đa nhiệm (multitasking). Những khả năng này nâng cao hiệu quả của máy tính. Các ngôn ngữ, do đó thường có thêm các hàm, thủ tục hay các biến cho phép người lập trình tận dụng chúng. Việc viết mã cho kiến trúc đa luồng và đa nhiệm không đơn giản như viết mã cho các hệ thống thông thường. Người lập trình ngoài kỹ năng viết mã, còn phải luyện tập cách xử lý và đồng bộ nhiều thao tác được thi hành đồng thời trong một chương trình mà không gây ra ách tắc hay vi phạm các nguyên tắc quản lý bộ nhớ hay các quy tắc lập trình theo đa luồng hay đa nhiệm.
Lưu ý : Hầu hết những hệ điều hành quản lý tương hỗ kiến trúc đa luồng hay đa nhiệm đều có năng lực thực thi những chương trình được tạo ra từ mã viết theo kiểu thường thì mà không đá động tới những công dụng đa luồng hay đa nhiệm. Điểm khác nhau là khi không dùng tới những ưu điểm đa luồng hay đa nhiệm thì chương trình đó sẽ không tận dụng được lợi thế phần cứng và ứng dụng tương hỗ ( thường thì chương trình đó chạy chậm hơn )
Phương ngữ và hiện thực[sửa|sửa mã nguồn]
Một phương ngữ (tiếng Anh: dialect) của một ngôn ngữ lập trình hay ngôn ngữ trao đổi dữ liệu là một biến thể (tương đổi nhỏ) hay phần mở rộng của ngôn ngữ đó mà không làm thay đổi bản chất bên trong của nó.
Nguồn tìm hiểu thêm[sửa|sửa mã nguồn]
Liên kết ngoài[sửa|sửa mã nguồn]
Source: https://vh2.com.vn
Category : Tin Học

Khởi động sao tam giác là một trong số những phương pháp để khởi động động cơ đơn giản, hiệu quả và tiết kiệm chi phí. Vậy Khởi động sao...
Đồ Án 2: Thiết kế mạch Buck Converter DC-DC Bạn đang xem bản rút gọn của tài liệu. Xem và tải ngay bản đầy đủ của tài liệu tại đây...
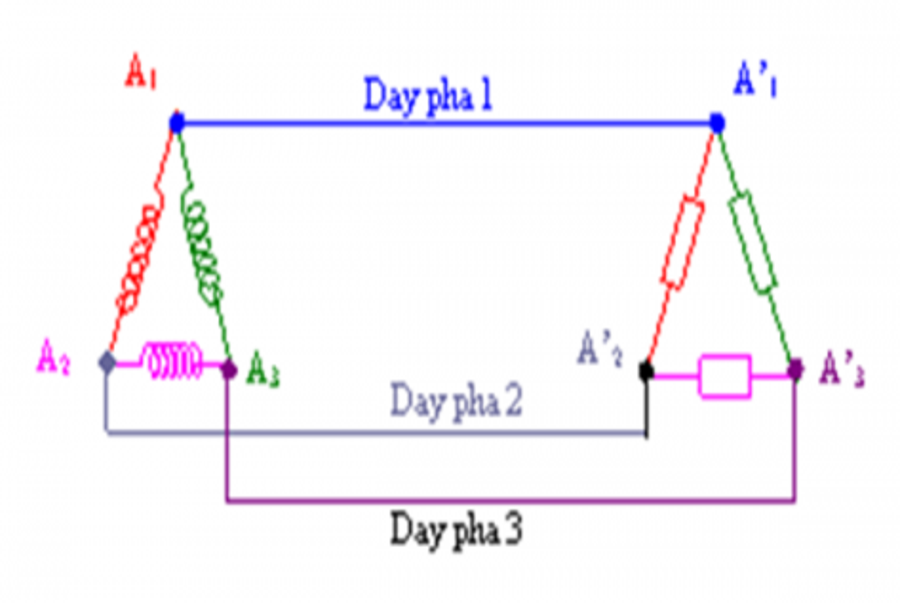
Nguyên tắc hoạt động máy phát điện xoay chiềuDựa trên hiện tượng cảm ứng điện từ: Khi từ thông qua một vòng dây biến thiên điều hòa, trong vòng dây...
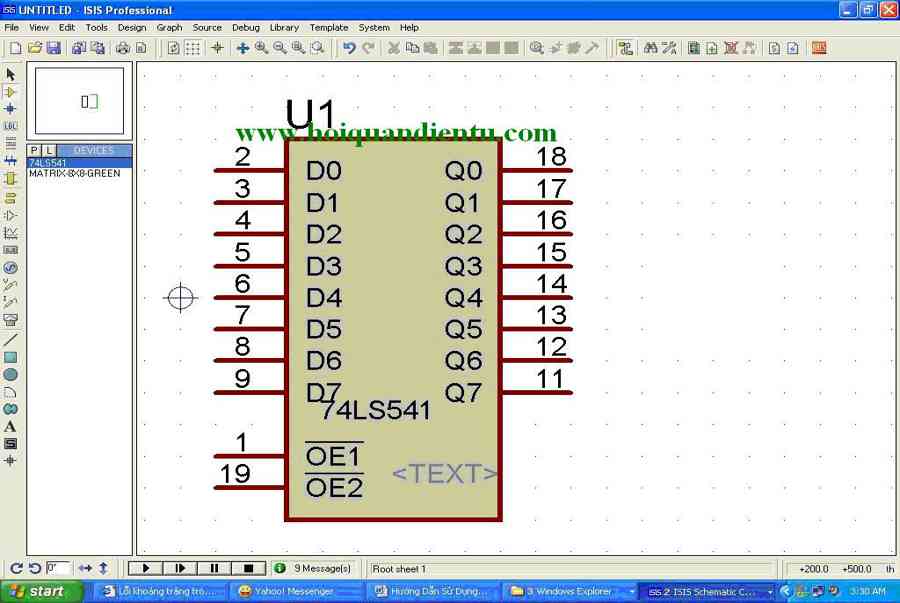
HDSD Led matrix Trong Proteus Và Cách Quét LED SD 8051 ( 8 x 64 ) Ngày 03/08/2010 20:19:50 / Lượt xem: 27279 / Người đăng: biendt / Nguồn: [email protected]...